Variational quantum eigensolver (VQE)
Pelajaran ini akan memperkenalkan variational quantum eigensolver, menjelaskan pentingnya algoritma ini sebagai fondasi dalam komputasi kuantum, serta mengeksplorasi kelebihan dan kelemahannya. VQE sendiri, tanpa metode pendukung, kemungkinan besar tidak cukup untuk komputasi kuantum skala utilitas modern. Meskipun begitu, algoritma ini tetap penting sebagai metode hibrida klasik-kuantum yang khas, dan merupakan fondasi penting bagi banyak algoritma yang lebih canggih.
Video ini memberikan gambaran umum tentang VQE dan faktor-faktor yang mempengaruhi efisiensinya. Teks di bawah ini menambahkan detail lebih lanjut dan mengimplementasikan VQE menggunakan Qiskit.
1. Apa itu VQE?
Variational quantum eigensolver adalah algoritma yang menggunakan komputasi klasik dan kuantum secara bersamaan untuk menyelesaikan suatu tugas. Ada empat komponen utama dalam perhitungan VQE:
- Sebuah operator: Biasanya sebuah Hamiltonian, yang akan kita sebut , yang menggambarkan suatu properti sistem yang ingin kamu optimalkan. Cara lain untuk menyebutnya adalah bahwa kamu mencari eigenvector dari operator ini yang bersesuaian dengan eigenvalue minimum. Eigenvector ini sering disebut "ground state".
- "Ansatz" (kata dalam bahasa Jerman yang berarti "pendekatan"): ini adalah Circuit kuantum yang mempersiapkan keadaan kuantum yang mendekati eigenvector yang dicari. Sebenarnya ansatz adalah sebuah keluarga Circuit kuantum, karena beberapa Gate dalam ansatz diparametrikan, yaitu diberi parameter yang bisa kita variasikan. Keluarga Circuit kuantum ini bisa mempersiapkan keluarga keadaan kuantum yang mendekati ground state.
- Sebuah Estimator: cara untuk mengestimasi nilai ekspektasi dari operator atas keadaan kuantum variasional saat ini. Terkadang yang benar-benar kita pedulikan hanyalah nilai ekspektasi ini, yang kita sebut fungsi biaya. Terkadang, kita peduli pada fungsi yang lebih kompleks yang masih bisa ditulis dari satu atau lebih nilai ekspektasi.
- Optimizer klasik: algoritma yang memvariasikan parameter untuk mencoba meminimalkan fungsi biaya.
Yuk kita lihat setiap komponen ini lebih dalam.
1.1 Operator (Hamiltonian)
Inti dari masalah VQE adalah operator yang menggambarkan sistem yang diminati. Kita asumsikan di sini bahwa eigenvalue terendah dan eigenvector yang bersesuaian dari operator ini berguna untuk tujuan ilmiah atau bisnis tertentu. Contohnya bisa berupa Hamiltonian kimia yang menggambarkan molekul, sehingga eigenvalue terendah dari operator bersesuaian dengan energi ground state molekul tersebut, dan eigenstate yang bersesuaian menggambarkan geometri atau konfigurasi elektron molekul. Atau operator bisa menggambarkan biaya dari proses tertentu yang akan dioptimalkan, dan eigenstate-nya bisa bersesuaian dengan rute atau praktik. Di beberapa bidang, seperti fisika, "Hamiltonian" hampir selalu merujuk pada operator yang menggambarkan energi sistem fisika. Tapi dalam komputasi kuantum, umum untuk melihat operator kuantum yang menggambarkan masalah bisnis atau logistik juga disebut "Hamiltonian". Kita akan mengadopsi konvensi tersebut di sini.

Pemetaan masalah fisika atau optimisasi ke qubit biasanya merupakan tugas yang tidak sepele, tetapi detail tersebut bukan fokus kursus ini. Diskusi umum tentang pemetaan masalah ke operator kuantum bisa ditemukan di Quantum computing in practice. Pandangan lebih detail tentang pemetaan masalah kimia ke operator kuantum bisa ditemukan di Quantum Chemistry with VQE.
Untuk tujuan kursus ini, kita akan mengasumsikan bahwa bentuk Hamiltonian sudah diketahui. Misalnya, Hamiltonian untuk molekul hidrogen sederhana (dengan asumsi active space tertentu, dan menggunakan Jordan-Wigner mapper) adalah:
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit qiskit-ibm-runtime scipy
from qiskit.quantum_info import SparsePauliOp
hamiltonian = SparsePauliOp(
[
"IIII",
"IIIZ",
"IZII",
"IIZI",
"ZIII",
"IZIZ",
"IIZZ",
"ZIIZ",
"IZZI",
"ZZII",
"ZIZI",
"YYYY",
"XXYY",
"YYXX",
"XXXX",
],
coeffs=[
-0.09820182 + 0.0j,
-0.1740751 + 0.0j,
-0.1740751 + 0.0j,
0.2242933 + 0.0j,
0.2242933 + 0.0j,
0.16891402 + 0.0j,
0.1210099 + 0.0j,
0.16631441 + 0.0j,
0.16631441 + 0.0j,
0.1210099 + 0.0j,
0.17504456 + 0.0j,
0.04530451 + 0.0j,
0.04530451 + 0.0j,
0.04530451 + 0.0j,
0.04530451 + 0.0j,
],
)
Perhatikan bahwa dalam Hamiltonian di atas, ada suku-suku seperti ZZII dan YYYY yang tidak saling komutasi. Artinya, untuk mengevaluasi ZZII, kita perlu mengukur operator Pauli Z pada qubit ke-3 (di antara pengukuran lainnya). Tapi untuk mengevaluasi YYYY, kita perlu mengukur operator Pauli Y pada qubit yang sama, yaitu qubit ke-3. Ada relasi ketidakpastian antara operator Y dan Z pada qubit yang sama; kita tidak bisa mengukur kedua operator tersebut secara bersamaan. Kita akan membahas kembali poin ini di bawah, dan memang sepanjang kursus ini.
Hamiltonian di atas adalah operator matriks . Mendiagonalisasi operator untuk menemukan eigenvalue energi terendahnya tidak terlalu sulit.
import numpy as np
A = np.array(hamiltonian)
eigenvalues, eigenvectors = np.linalg.eigh(A)
print("The ground state energy is ", min(eigenvalues), "hartrees")
The ground state energy is -1.1459778447627311 hartrees
Eigensolver klasik brute force tidak bisa diskalakan untuk menggambarkan energi atau geometri sistem atom yang sangat besar, seperti obat-obatan atau protein. VQE adalah salah satu upaya awal untuk memanfaatkan komputasi kuantum dalam masalah ini.
Kita akan menemukan Hamiltonian dalam pelajaran ini yang jauh lebih besar dari yang di atas. Tapi akan mubazir untuk mendorong batas-batas kemampuan VQE, sebelum kita memperkenalkan beberapa alat yang lebih canggih yang bisa memperkuat atau menggantikan VQE, nanti dalam kursus ini.
1.2 Ansatz
Kata "ansatz" dalam bahasa Jerman berarti "pendekatan". Bentuk jamul yang benar dalam bahasa Jerman adalah "ansätze", meski sering terlihat "ansatzes" atau "ansatze". Dalam konteks VQE, ansatz adalah Circuit kuantum yang digunakan untuk membuat fungsi gelombang multi-qubit yang paling mendekati ground state sistem yang sedang dipelajari, dan dengan demikian menghasilkan nilai ekspektasi terendah dari operator kamu. Circuit kuantum ini akan berisi parameter variasional (sering dikumpulkan dalam vektor variabel ).

Sebuah set nilai awal dari parameter variasional dipilih. Kita akan menyebut operasi unitary dari ansatz pada Circuit . Secara default, semua qubit dalam komputer kuantum IBM® diinisialisasi ke keadaan . Ketika Circuit dijalankan, keadaan qubit akan menjadi
Jika yang kita butuhkan hanyalah energi terendah (menggunakan bahasa sistem fisika), kita bisa mengestimasinya dengan cara sederhana mengukur energi berkali-kali dan mengambil yang terendah. Tapi kita biasanya juga menginginkan konfigurasi yang menghasilkan energi atau eigenvalue terendah tersebut. Jadi langkah selanjutnya adalah estimasi nilai ekspektasi dari Hamiltonian, yang dicapai melalui pengukuran kuantum. Banyak yang terlibat di sana. Tapi kita bisa memahami proses ini secara kualitatif dengan mencatat bahwa probabilitas mengukur energi (lagi-lagi menggunakan bahasa sistem fisika) terkait dengan nilai ekspektasi oleh:
Probabilitas juga terkait dengan overlap antara eigenstate dan keadaan sistem saat ini :
Jadi dengan membuat banyak pengukuran operator Pauli yang membentuk Hamiltonian kita, kita bisa mengestimasi nilai ekspektasi Hamiltonian dalam keadaan sistem saat ini . Langkah selanjutnya adalah memvariasikan parameter dan mencoba untuk lebih mendekati keadaan terendah-energi (ground) dari sistem. Karena parameter variasional dalam ansatz, kadang-kadang disebut sebagai variational form.
Sebelum kita melanjutkan ke proses variasional tersebut, perhatikan bahwa sering berguna untuk memulai keadaan kamu dari keadaan "tebakan awal yang baik". Kamu mungkin tahu cukup banyak tentang sistemmu untuk membuat tebakan awal yang lebih baik dari . Misalnya, umum untuk menginisialisasi qubit ke keadaan Hartree-Fock dalam aplikasi kimia. Tebakan awal yang tidak mengandung parameter variasional ini disebut reference state. Sebut Circuit kuantum yang digunakan untuk membuat reference state . Kapanpun penting untuk membedakan reference state dari sisa ansatz, gunakan: Atau secara ekuivalen
1.3 Estimator
Kita perlu cara untuk mengestimasi nilai ekspektasi Hamiltonian dalam keadaan variasional tertentu . Jika kita bisa mengukur langsung seluruh operator , ini akan sesederhana membuat banyak (katakanlah ) pengukuran dan merata-rata nilai yang diukur:
Di sini, simbol mengingatkan kita bahwa nilai ekspektasi ini hanya akan tepat dalam limit ketika . Tapi dengan ribuan pengukuran yang dilakukan pada Circuit, kesalahan sampling dari nilai ekspektasi cukup rendah. Ada pertimbangan lain seperti noise yang menjadi masalah untuk perhitungan yang sangat presisi.
Namun, umumnya tidak mungkin untuk mengukur sekaligus. mungkin mengandung banyak operator Pauli X, Y, dan Z yang tidak saling komutasi. Jadi Hamiltonian harus dipecah menjadi kelompok-kelompok operator yang bisa diukur secara bersamaan, dan setiap kelompok tersebut harus diestimasi secara terpisah, lalu hasilnya digabungkan untuk mendapatkan nilai ekspektasi. Kita akan membahas ini secara lebih detail di pelajaran berikutnya, ketika kita mendiskusikan skala pendekatan klasik dan kuantum. Kompleksitas dalam pengukuran ini adalah salah satu alasan kita membutuhkan kode yang sangat efisien untuk melakukan estimasi tersebut. Dalam pelajaran ini dan seterusnya, kita akan menggunakan primitif Qiskit Runtime yaitu Estimator untuk tujuan ini.
1.4 Optimizer klasik
Optimizer klasik adalah algoritma klasik apa pun yang dirancang untuk menemukan ekstrema dari fungsi target (biasanya minimum). Mereka menelusuri ruang parameter yang mungkin untuk menemukan set yang meminimalkan beberapa fungsi yang diminati. Secara umum bisa dikategorikan menjadi metode berbasis gradien, yang memanfaatkan informasi gradien, dan metode bebas gradien, yang beroperasi sebagai optimizer black-box. Pilihan optimizer klasik bisa secara signifikan mempengaruhi kinerja algoritma, terutama dengan adanya noise dalam hardware kuantum. Optimizer populer di bidang ini antara lain Adam, AMSGrad, dan SPSA, yang telah menunjukkan hasil yang menjanjikan dalam lingkungan yang noisy. Optimizer yang lebih tradisional termasuk COBYLA dan SLSQP.
Alur kerja umum (ditunjukkan dalam Bagian 3.3) adalah menggunakan salah satu algoritma ini sebagai metode di dalam minimizer seperti fungsi minimize dari scipy. Ini mengambil sebagai argumen:
- Beberapa fungsi yang akan diminimalkan. Ini sering berupa nilai ekspektasi energi. Tapi ini umumnya disebut sebagai "fungsi biaya".
- Sebuah set parameter dari mana pencarian dimulai. Sering disebut atau .
- Argumen, termasuk argumen fungsi biaya. Dalam komputasi kuantum dengan Qiskit, argumen-argumen ini akan mencakup ansatz, Hamiltonian, dan primitif Estimator, yang dibahas lebih lanjut di subbagian berikutnya.
- Sebuah 'method' minimisasi. Ini merujuk pada algoritma spesifik yang digunakan untuk menelusuri ruang parameter. Di sinilah kita akan menentukan, misalnya, COBYLA atau SLSQP.
- Opsi. Opsi yang tersedia mungkin berbeda per metode. Tapi contoh yang hampir semua metode miliki adalah jumlah iterasi maksimum dari optimizer sebelum mengakhiri pencarian: 'maxiter'.

Pada setiap langkah iteratif, nilai ekspektasi Hamiltonian diestimasi dengan membuat banyak pengukuran. Energi yang diestimasi ini dikembalikan oleh fungsi biaya, dan minimizer memperbarui informasi yang dimilikinya tentang lanskap energi. Apa yang dilakukan optimizer untuk memilih langkah berikutnya bervariasi dari metode ke metode. Beberapa menggunakan gradien dan memilih arah penurunan tercuram. Yang lain mungkin memperhitungkan noise dan mungkin mengharuskan biaya turun dengan margin besar sebelum menerima bahwa energi sebenarnya turun ke arah tersebut.
# Example syntax for minimization
# from scipy.optimize import minimize
# res = minimize(cost_func, x0, args=(ansatz, hamiltonian, estimator), method="cobyla",
# options={'maxiter': 200})
1.5 Prinsip variasional
Dalam konteks ini prinsip variasional sangat penting; ia menyatakan bahwa tidak ada fungsi gelombang variasional yang bisa menghasilkan nilai ekspektasi energi (atau biaya) yang lebih rendah dari yang dihasilkan oleh fungsi gelombang ground state. Secara matematis,
Ini mudah diverifikasi jika kita perhatikan bahwa set semua eigenstate dari membentuk basis lengkap untuk ruang Hilbert. Dengan kata lain, setiap keadaan dan khususnya bisa ditulis sebagai jumlah berbobot (ternormalisasi) dari eigenstate-eigenstate ini:
di mana adalah konstanta yang akan ditentukan, dan . Kita serahkan ini sebagai latihan untuk pembaca. Tapi perhatikan implikasinya: keadaan variasional yang menghasilkan nilai ekspektasi energi terendah adalah estimasi terbaik dari ground state yang sebenarnya.
Uji pemahamanmu
Verifikasi secara matematis bahwa untuk keadaan variasional mana pun.
Jawaban
Menggunakan ekspansi keadaan variasional dalam hal eigenstate energi yang diberikan,
kita bisa menuliskan nilai ekspektasi energi variasional sebagai
Untuk semua koefisien . Sehingga kita bisa menulis
2. Perbandingan dengan alur kerja klasik
Katakanlah kita tertarik pada sebuah matriks dengan N baris dan N kolom. Misalkan matriksmu begitu besar sehingga diagonalisasi eksak bukan pilihan. Anggap lebih lanjut bahwa kamu tahu cukup tentang masalahmu untuk membuat beberapa tebakan tentang struktur keseluruhan dari eigenstate target, dan kamu ingin menguji keadaan yang mirip dengan tebakanmu untuk melihat apakah biaya/energimu bisa diturunkan lebih jauh. Ini adalah pendekatan variasional, dan merupakan salah satu metode yang digunakan ketika diagonalisasi eksak bukan pilihan.
2.1 Alur kerja klasik
Menggunakan komputer klasik, ini akan bekerja sebagai berikut:
- Buat keadaan tebakan, dengan beberapa parameter yang akan kamu variasikan: . Meskipun tebakan awal ini bisa acak, itu tidak disarankan. Kita ingin menggunakan pengetahuan tentang masalah yang ada untuk menyesuaikan tebakan kita sebisa mungkin.
- Hitung nilai ekspektasi operator dengan sistem dalam keadaan tersebut:
- Ubah parameter variasional dan ulangi: .
- Gunakan informasi yang terkumpul tentang lanskap keadaan yang mungkin dalam subruang variasionalmu untuk membuat tebakan yang semakin baik dan mendekati keadaan target. Prinsip variasional menjamin bahwa keadaan variasional kita tidak bisa menghasilkan eigenvalue yang lebih rendah dari eigenvalue ground state target. Jadi semakin rendah nilai ekspektasinya semakin baik aproksimasi ground state kita:
Mari kita periksa kesulitan setiap langkah dalam pendekatan ini. Mengatur atau memperbarui parameter secara komputasi mudah; kesulitannya ada pada pemilihan parameter awal yang berguna dan bermotivasi fisika. Menggunakan informasi yang terkumpul dari iterasi sebelumnya untuk memperbarui parameter sedemikian rupa sehingga kamu mendekati ground state tidaklah sepele. Tapi algoritma optimisasi klasik ada yang melakukan ini dengan cukup efisien. Optimisasi klasik ini hanya mahal karena mungkin membutuhkan banyak iterasi; dalam kasus terburuk, jumlah iterasi bisa bertambah secara eksponensial dengan N. Langkah tunggal yang paling mahal secara komputasi hampir pasti adalah menghitung nilai ekspektasi matriksmu menggunakan keadaan tertentu :
Matriks harus bekerja pada vektor -elemen, yang bersesuaian dengan: operasi perkalian dalam kasus terburuk. Ini harus dilakukan pada setiap iterasi parameter. Untuk matriks yang sangat besar, ini memiliki biaya komputasi yang tinggi.
2.2 Alur kerja kuantum dan kelompok Pauli yang komutasi
Sekarang bayangkan merelokasikan bagian perhitungan ini ke komputer kuantum. Alih-alih menghitung nilai ekspektasi ini, kamu mengestimasinya dengan mempersiapkan keadaan pada komputer kuantum menggunakan ansatz variasionalmu, lalu membuat pengukuran.
Itu mungkin terdengar lebih mudah dari kenyataannya. umumnya tidak mudah diukur. Misalnya bisa terdiri dari banyak operator Pauli X, Y, dan Z yang tidak saling komutasi. Tapi bisa ditulis sebagai kombinasi linear dari suku-suku, , yang masing-masing mudah diukur (misalnya, operator Pauli atau kelompok operator Pauli yang komutasi qubit-wise). Nilai ekspektasi atas beberapa keadaan adalah jumlah berbobot dari nilai ekspektasi suku-suku konstituen . Ekspresi ini berlaku untuk keadaan apa pun, tapi kita akan menggunakannya secara khusus dengan keadaan variasional .
di mana adalah string Pauli seperti IZZX…XIYX, atau beberapa string tersebut yang saling komutasi. Jadi deskripsi nilai ekspektasi yang lebih dekat mencerminkan kenyataan pengukuran pada komputer kuantum adalah
Dan dalam konteks fungsi gelombang variasional kita:
Setiap suku bisa diukur kali menghasilkan sampel pengukuran dengan dan mengembalikan nilai ekspektasi dan deviasi standar . Kita bisa menjumlahkan suku-suku ini dan merambatkan kesalahan melalui jumlah tersebut untuk mendapatkan nilai ekspektasi keseluruhan dan deviasi standar .
Ini tidak memerlukan perkalian berskala besar, maupun proses yang skala seperti . Sebaliknya memerlukan beberapa pengukuran pada komputer kuantum. Jika kamu tidak membutuhkan terlalu banyak dari itu, pendekatan ini bisa efisien. Dan itulah bagian kuantum dari VQE.
Tapi mari kita bicara tentang alasan mengapa ini mungkin tidak efisien. Salah satu alasan banyak pengukuran adalah untuk mengurangi ketidakpastian statistik dalam estimasimu, untuk perhitungan yang sangat presisi. Alasan lainnya adalah jumlah string Pauli yang diperlukan untuk mencakup seluruh matriksmu. Karena matriks Pauli (ditambah identitas: X, Y, Z, dan I) mencakup ruang semua operator dari dimensi tertentu, kita dijamin bisa menulis matriks yang diminati sebagai jumlah berbobot operator Pauli, seperti yang kita lakukan sebelumnya.
di mana adalah string Pauli yang bekerja pada semua qubit yang menggambarkan sistemmu seperti IZZX…XIYX, atau beberapa string tersebut yang saling komutasi. Ingat bahwa Qiskit menggunakan notasi little endian, di mana operator Pauli ke- dari kanan bekerja pada qubit ke-. Jadi kita bisa mengukur operator kita dengan mengukur serangkaian operator Pauli.
Tapi kita tidak bisa mengukur semua operator Pauli tersebut secara bersamaan. Operator Pauli (tidak termasuk I) tidak komutasi satu sama lain jika terkait dengan qubit yang sama. Misalnya, kita bisa mengukur IZIZ dan ZZXZ secara bersamaan, karena kita bisa mengukur I dan Z secara bersamaan untuk qubit ketiga, dan kita bisa mengetahui I dan X secara bersamaan untuk qubit pertama. Tapi kita tidak bisa mengukur ZZZZ dan ZZZX secara bersamaan, karena Z dan X tidak komutasi, dan keduanya bekerja pada qubit ke-0. Pembaca yang berpengalaman mungkin ingat bahwa dua kelompok operator Pauli mungkin komutasi sebagai satu set meskipun pengukuran masing-masing qubit tidak komutasi. Estimator mengasumsikan pengukuran Pauli tensor-product (melalui rotasi basis), yang sesuai dengan pengelompokan operator yang qubit-wise commuting. Jadi untuk mengestimasi secara bersamaan dua string (A dan B) operator Pauli menggunakan Estimator, operator Pauli dari setiap qubit di A dan B harus komutasi. Ini berarti kita juga tidak bisa mengukur ZZZZ dan ZZXX secara bersamaan.

Jadi kita menguraikan matriks kita menjadi jumlah Pauli yang bekerja pada qubit yang berbeda. Beberapa elemen dari jumlah tersebut bisa diukur sekaligus; kita menyebut ini kelompok Pauli yang komutasi. Tergantung pada berapa banyak suku yang tidak komutasi, kita mungkin membutuhkan banyak kelompok seperti itu. Sebut jumlah kelompok string Pauli yang komutasi tersebut . Jika kecil, ini bisa bekerja dengan baik. Jika memiliki jutaan kelompok, ini tidak akan berguna.
Proses-proses yang diperlukan untuk estimasi nilai ekspektasi dikumpulkan bersama dalam primitif Qiskit Runtime yang disebut Estimator. Untuk mempelajari lebih lanjut tentang Estimator, lihat referensi API di IBM Quantum® Documentation. Seseorang bisa menggunakan Estimator secara langsung, tapi Estimator mengembalikan lebih dari sekadar eigenvalue energi terendah. Misalnya, ia juga mengembalikan informasi tentang standard error ensemble. Jadi, dalam konteks masalah minimisasi, sering terlihat Estimator di dalam fungsi biaya. Untuk mempelajari lebih lanjut tentang input dan output Estimator lihat panduan ini di IBM Quantum Documentation.
Kamu mencatat nilai ekspektasi (atau fungsi biaya) untuk set parameter yang digunakan dalam keadaanmu, lalu memperbarui parameter. Seiring waktu, kamu bisa menggunakan nilai ekspektasi atau nilai fungsi biaya yang telah kamu estimasi untuk mengaproksimasi gradien dari fungsi biayamu dalam subruang keadaan yang diambil sampelnya oleh ansatzmu. Optimizer klasik berbasis gradien maupun bebas gradien ada. Keduanya rentan terhadap masalah keterlatiahan, seperti banyak minimum lokal, dan wilayah besar ruang parameter dengan gradien mendekati nol, yang disebut barren plateaus.

2.3 Faktor-faktor yang menentukan biaya komputasi
VQE tidak akan menyelesaikan semua masalah kimia kuantum terberatmu. Tidak. Tapi menjadi lebih baik di semua perhitungan bukan poinnya. Kita telah menggeser apa yang menentukan biaya komputasi.

Kita telah bergeser dari proses yang kompleksitasnya hanya bergantung pada dimensi matriks ke satu yang bergantung pada presisi yang diperlukan dan jumlah operator Pauli yang tidak komutasi yang membentuk matriks. Bagian terakhir tidak memiliki analogi dalam komputasi klasik.
Berdasarkan dependensi ini, untuk matriks yang sparse, atau matriks yang melibatkan sedikit string Pauli yang tidak komutasi, proses ini mungkin berguna. Ini adalah kasusnya untuk sistem spin yang berinteraksi, misalnya. Untuk matriks yang padat, mungkin kurang berguna. Kita tahu misalnya bahwa sistem kimia sering memiliki Hamiltonian yang melibatkan ratusan, ribuan, bahkan jutaan string Pauli. Ada karya menarik yang telah dilakukan untuk mengurangi jumlah suku ini. Tapi sistem kimia mungkin lebih cocok untuk beberapa algoritma lain yang akan kita diskusikan dalam kursus ini.
Uji pemahamanmu
Perhatikan sebuah Hamiltonian pada empat qubit yang mengandung suku-suku:
IIXX, IIXZ, IIZZ, IZXZ, IXXZ, ZZXZ, XZXZ, ZIXZ, ZZZZ, XXXX
Kamu ingin mengurutkan suku-suku ini ke dalam kelompok-kelompok sehingga semua suku dalam satu kelompok bisa diukur secara bersamaan. Berapa jumlah minimum kelompok yang bisa kamu buat sehingga semua suku tercakup?
Jawaban
Bisa dilakukan dalam 4 kelompok. Perhatikan bahwa solusi seperti ini biasanya tidak unik.
IIXX, XXXX, IIZZ, ZZZZ
IIXZ, IZXZ, ZIXZ, ZZXZ
IXXZ
XZXZ
Mana yang menurut kamu biasanya membuat kimia kuantum dengan VQE sulit: jumlah suku dalam Hamiltonian, atau menemukan ansatz yang baik?
Jawaban
Ternyata ada ansätze yang sangat dioptimalkan untuk konteks kimia. Jumlah suku dalam Hamiltonian, dan karenanya jumlah pengukuran yang diperlukan biasanya menimbulkan lebih banyak masalah.
3. Contoh Hamiltonian
Mari kita terapkan algoritma ini secara praktis menggunakan matriks Hamiltonian kecil agar kita bisa melihat apa yang terjadi di setiap langkah. Kita akan menggunakan framework Qiskit patterns:
-Langkah 1: Petakan masalah ke sirkuit dan operator kuantum -Langkah 2: Optimalkan untuk hardware target -Langkah 3: Jalankan di hardware target -Langkah 4: Proses hasil pasca-eksekusi
3.1 Langkah 1: Petakan masalah ke sirkuit dan operator kuantum
Kita akan menggunakan yang sudah didefinisikan di atas dari konteks kimia. Kita mulai dengan beberapa import umum.
# General imports
import numpy as np
# SciPy minimizer routine
from scipy.optimize import minimize
# Plotting functions
import matplotlib.pyplot as plt
Sekali lagi, kita asumsikan Hamiltonian yang diinginkan sudah diketahui. Kita akan menggunakan Hamiltonian yang sangat kecil di sini, karena metode lain yang dibahas dalam kursus ini akan lebih efisien untuk memecahkan masalah yang lebih besar.
from qiskit.quantum_info import SparsePauliOp
import numpy as np
hamiltonian = SparsePauliOp.from_list(
[("YZ", 0.3980), ("ZI", -0.3980), ("ZZ", -0.0113), ("XX", 0.1810)]
)
A = np.array(hamiltonian)
eigenvalues, eigenvectors = np.linalg.eigh(A)
print("The ground state energy is ", min(eigenvalues))
The ground state energy is -0.702930394459531
Ada banyak pilihan ansatz siap pakai di Qiskit. Kita akan menggunakan efficient_su2.
# Pre-defined ansatz circuit and operator class for Hamiltonian
from qiskit.circuit.library import efficient_su2
# Note that it is more common to place initial 'h' gates outside the ansatz.
# Here we specifically wanted this layer structure.
ansatz = efficient_su2(
hamiltonian.num_qubits, su2_gates=["h", "rz", "y"], entanglement="circular", reps=1
)
num_params = ansatz.num_parameters
print("This circuit has ", num_params, "parameters")
ansatz.decompose().draw("mpl", style="iqp")
This circuit has 4 parameters
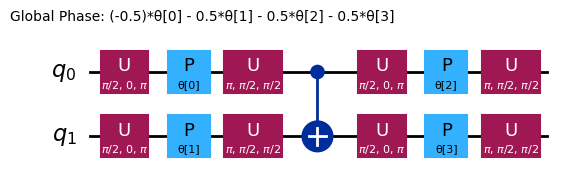
Ansatz yang berbeda akan memiliki struktur entanglement dan gate rotasi yang berbeda. Yang ditampilkan di sini menggunakan gate CNOT untuk entanglement, serta gate Y dan gate RZ berparameter untuk rotasi. Perhatikan ukuran ruang parameter ini; artinya kita harus meminimalkan fungsi biaya terhadap 4 variabel (parameter untuk gate RZ). Ini bisa diskalakan, tapi tidak tanpa batas. Menjalankan masalah serupa pada 4 qubit, menggunakan default 3 reps untuk efficient_su2 menghasilkan 16 parameter variasional.
3.2 Langkah 2: Optimalkan untuk hardware target
Ansatz ditulis menggunakan gate yang sudah familiar, tapi sirkuit kita harus ditranspilasi agar bisa menggunakan gate basis yang bisa diimplementasikan di setiap komputer kuantum. Kita pilih Backend yang paling tidak sibuk.
# runtime imports
from qiskit_ibm_runtime import QiskitRuntimeService, Session
from qiskit_ibm_runtime import EstimatorV2 as Estimator
# To run on hardware, select the backend with the fewest number of jobs in the queue
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
print(backend)
<IBMBackend('ibm_torino')>
Sekarang kita bisa mentranspilasi sirkuit kita untuk hardware ini dan memvisualisasikan ansatz yang sudah ditranspilasi.
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
target = backend.target
pm = generate_preset_pass_manager(target=target, optimization_level=3)
ansatz_isa = pm.run(ansatz)
ansatz_isa.draw(output="mpl", idle_wires=False, style="iqp")

Perhatikan bahwa gate yang digunakan sudah berubah, dan qubit dalam sirkuit abstrak kita telah dipetakan ke qubit bernomor berbeda di komputer kuantum. Kita harus memetakan Hamiltonian kita secara identik agar hasilnya bermakna.
hamiltonian_isa = hamiltonian.apply_layout(layout=ansatz_isa.layout)
3.3 Langkah 3: Jalankan di hardware target
3.3.1 Melaporkan nilai
Kita mendefinisikan fungsi biaya di sini yang mengambil argumen berupa struktur yang sudah kita bangun di langkah sebelumnya: parameter, ansatz, dan Hamiltonian. Fungsi ini juga menggunakan Estimator, yang belum kita definisikan. Kita sertakan kode untuk melacak riwayat fungsi biaya, agar kita bisa memeriksa perilaku konvergensinya.
def cost_func(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from Estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (EstimatorV2): Estimator primitive instance
cost_history_dict: Dictionary for storing intermediate results
Returns:
float: Energy estimate
"""
pub = (ansatz, [hamiltonian], [params])
result = estimator.run(pubs=[pub]).result()
energy = result[0].data.evs[0]
cost_history_dict["iters"] += 1
cost_history_dict["prev_vector"] = params
cost_history_dict["cost_history"].append(energy)
print(f"Iters. done: {cost_history_dict['iters']} [Current cost: {energy}]")
return energy
cost_history_dict = {
"prev_vector": None,
"iters": 0,
"cost_history": [],
}
Akan sangat menguntungkan jika kamu bisa memilih nilai parameter awal berdasarkan pengetahuan tentang masalah yang dihadapi dan karakteristik state target. Kita tidak akan membuat asumsi seperti itu dan akan menggunakan nilai awal acak.
x0 = 2 * np.pi * np.random.random(num_params)
# This required 13 min, 20 s QPU time on an Eagle processor, 28 min total time.
with Session(backend=backend) as session:
estimator = Estimator(mode=session)
estimator.options.default_shots = 10000
res = minimize(
cost_func,
x0,
args=(ansatz_isa, hamiltonian_isa, estimator),
method="cobyla",
options={"maxiter": 50},
)
Iters. done: 1 [Current cost: 0.010575798722044727]
Iters. done: 2 [Current cost: 0.004040015974440895]
Iters. done: 3 [Current cost: 0.0020213258785942503]
Iters. done: 4 [Current cost: 0.18723082446726014]
Iters. done: 5 [Current cost: -0.2746792152068885]
Iters. done: 6 [Current cost: -0.3094547651648519]
Iters. done: 7 [Current cost: -0.05281985428356641]
Iters. done: 8 [Current cost: 0.00808560303514377]
Iters. done: 9 [Current cost: -0.0014821685303514388]
Iters. done: 10 [Current cost: -0.004759824281150161]
Iters. done: 11 [Current cost: 0.09942328705995292]
Iters. done: 12 [Current cost: 0.01092366214057508]
Iters. done: 13 [Current cost: 0.05017497496069776]
Iters. done: 14 [Current cost: 0.13028868414310696]
Iters. done: 15 [Current cost: 0.013747803514376994]
Iters. done: 16 [Current cost: 0.2583072432944498]
Iters. done: 17 [Current cost: -0.14422125655131562]
Iters. done: 18 [Current cost: -0.0004950150347678081]
Iters. done: 19 [Current cost: 0.00681082268370607]
Iters. done: 20 [Current cost: -0.0023377795527156544]
Iters. done: 21 [Current cost: 0.6027665591169237]
Iters. done: 22 [Current cost: 0.00596641373801917]
Iters. done: 23 [Current cost: -0.008318769968051117]
Iters. done: 24 [Current cost: -0.00026683306709265246]
Iters. done: 25 [Current cost: -0.007648222843450479]
Iters. done: 26 [Current cost: 0.004121086261980831]
Iters. done: 27 [Current cost: -0.004075019968051117]
Iters. done: 28 [Current cost: -0.004419369009584665]
Iters. done: 29 [Current cost: 0.213185460054037]
Iters. done: 30 [Current cost: -0.06505919572162797]
Iters. done: 31 [Current cost: -0.5334241316590271]
Iters. done: 32 [Current cost: 0.00218370607028754]
Iters. done: 33 [Current cost: 0.09579352143666908]
Iters. done: 34 [Current cost: -0.009274800319488819]
Iters. done: 35 [Current cost: -0.44395141360688106]
Iters. done: 36 [Current cost: 0.011747104632587858]
Iters. done: 37 [Current cost: -0.003344149361022364]
Iters. done: 38 [Current cost: 0.19138183916486304]
Iters. done: 39 [Current cost: 0.013513931813145209]
Kita bisa melihat output mentahnya.
res
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -0.5334241316590271
x: [ 1.024e+00 6.459e+00 3.625e+00 4.007e+00]
nfev: 39
maxcv: 0.0
3.4 Langkah 4: Proses hasil pasca-eksekusi
Jika prosedur berakhir dengan benar, maka nilai dalam dictionary kita seharusnya sama dengan vektor solusi dan jumlah total evaluasi fungsi. Ini mudah diverifikasi:
cost_history_dict
{'prev_vector': array([1.02397956, 6.45886604, 3.62479262, 4.00744128]),
'iters': 39,
'cost_history': [np.float64(0.010575798722044727),
np.float64(0.004040015974440895),
np.float64(0.0020213258785942503),
np.float64(0.18723082446726014),
np.float64(-0.2746792152068885),
np.float64(-0.3094547651648519),
np.float64(-0.05281985428356641),
np.float64(0.00808560303514377),
np.float64(-0.0014821685303514388),
np.float64(-0.004759824281150161),
np.float64(0.09942328705995292),
np.float64(0.01092366214057508),
np.float64(0.05017497496069776),
np.float64(0.13028868414310696),
np.float64(0.013747803514376994),
np.float64(0.2583072432944498),
np.float64(-0.14422125655131562),
np.float64(-0.0004950150347678081),
np.float64(0.00681082268370607),
np.float64(-0.0023377795527156544),
np.float64(0.6027665591169237),
np.float64(0.00596641373801917),
np.float64(-0.008318769968051117),
np.float64(-0.00026683306709265246),
np.float64(-0.007648222843450479),
np.float64(0.004121086261980831),
np.float64(-0.004075019968051117),
np.float64(-0.004419369009584665),
np.float64(0.213185460054037),
np.float64(-0.06505919572162797),
np.float64(-0.5334241316590271),
np.float64(0.00218370607028754),
np.float64(0.09579352143666908),
np.float64(-0.009274800319488819),
np.float64(-0.44395141360688106),
np.float64(0.011747104632587858),
np.float64(-0.003344149361022364),
np.float64(0.19138183916486304),
np.float64(0.013513931813145209)]}
fig, ax = plt.subplots()
x = np.linspace(0, 10, 50)
# Define the constant function
constant = -0.7029
y_constant = np.full_like(x, constant)
ax.plot(
range(cost_history_dict["iters"]), cost_history_dict["cost_history"], label="VQE"
)
ax.set_xlabel("Iterations")
ax.set_ylabel("Cost")
ax.plot(y_constant, label="Target")
plt.legend()
plt.draw()

IBM Quantum memiliki penawaran peningkatan keterampilan lain yang terkait dengan VQE. Jika kamu siap mempraktikkan VQE, lihat tutorial kami: Ground-state energy estimation of the Heisenberg chain with VQE. Jika kamu ingin informasi lebih lanjut tentang membuat Hamiltonian molekuler, lihat pelajaran ini dalam kursus kami tentang Quantum chemistry with VQE. Jika kamu tertarik untuk memahami lebih dalam cara kerja algoritma variasional seperti VQE, kami merekomendasikan kursus Variational Algorithm Design.
Uji pemahamanmu
Dalam bagian ini, kita menghitung energi ground state dari sebuah Hamiltonian. Jika kita ingin menerapkan ini untuk, misalnya, menentukan geometri sebuah molekul, bagaimana cara kita memperluasnya?
Jawaban
Kita perlu memperkenalkan variabel untuk jarak antar atom, dan sudut antara ikatan. Kita perlu memvariasikan ini. Untuk setiap variasi tersebut, kita akan menghasilkan Hamiltonian baru (karena operator yang mendeskripsikan energi tentu bergantung pada geometri). Untuk setiap Hamiltonian yang dihasilkan dan dipetakan ke qubit, kita perlu melakukan optimasi seperti yang dilakukan di atas. Dari semua masalah optimasi yang telah konvergen itu, geometri yang menghasilkan energi terendah adalah yang diadopsi oleh alam. Ini jauh lebih rumit dari yang ditampilkan di atas. Perhitungan seperti itu dilakukan untuk molekul paling sederhana, , di sini.
4. Hubungan VQE dengan metode lain
Dalam bagian ini kita akan meninjau kelebihan dan kekurangan pendekatan VQE asli serta menunjukkan hubungannya dengan algoritma lain yang lebih baru.
4.1 Kekuatan dan kelemahan VQE
Beberapa kekuatan sudah disebutkan sebelumnya. Antara lain:
- Cocok untuk hardware modern: Beberapa algoritma kuantum memerlukan tingkat error yang jauh lebih rendah, mendekati toleransi kesalahan skala besar. VQE tidak; VQE bisa diimplementasikan di komputer kuantum saat ini.
- Sirkuit dangkal: VQE sering menggunakan sirkuit kuantum yang relatif dangkal. Ini membuat VQE kurang rentan terhadap akumulasi kesalahan gate dan membuatnya cocok untuk banyak teknik mitigasi error. Tentu saja, sirkuitnya tidak selalu dangkal; ini tergantung pada ansatz yang digunakan.
- Keserbagunaan: VQE (pada prinsipnya) bisa diterapkan pada masalah apa pun yang bisa dirumuskan sebagai masalah nilai eigen/vektor eigen. Ada banyak peringatan yang membuat VQE tidak praktis atau tidak menguntungkan untuk beberapa masalah. Beberapa di antaranya dirangkum di bawah.
Beberapa kelemahan VQE dan masalah di mana VQE tidak praktis juga sudah dijelaskan di atas. Antara lain:
- Sifat heuristik: VQE tidak menjamin konvergensi ke energi ground state yang benar, karena kinerjanya bergantung pada pilihan ansatz dan metode optimasi[1-2]. Jika ansatz yang buruk dipilih karena kurang memiliki entanglement yang diperlukan untuk ground state yang diinginkan, tidak ada optimizer klasik yang bisa mencapai ground state tersebut.
- Parameter yang berpotensi sangat banyak: Ansatz yang sangat ekspresif mungkin memiliki begitu banyak parameter sehingga iterasi minimasi menjadi sangat memakan waktu.
- Overhead pengukuran yang tinggi: Dalam VQE, Estimator digunakan untuk memperkirakan nilai ekspektasi setiap suku dalam Hamiltonian. Sebagian besar Hamiltonian yang menarik akan memiliki suku-suku yang tidak bisa diperkirakan secara bersamaan. Ini bisa membuat VQE boros sumber daya untuk sistem besar dengan Hamiltonian yang rumit[1].
- Efek noise: Ketika optimizer klasik mencari minimum, perhitungan yang noisy bisa membingungkannya dan mengarahkannya menjauh dari minimum sejati atau menunda konvergensinya. Salah satu solusi yang mungkin adalah memanfaatkan teknik mitigasi error dan supresi error mutakhir[2-3] dari IBM.
- Barren plateau: Wilayah gradien yang menghilang[2-3] ini ada bahkan tanpa adanya noise, tapi noise membuatnya lebih bermasalah karena perubahan nilai ekspektasi akibat noise bisa lebih besar dari perubahan akibat pembaruan parameter di wilayah barren ini.
4.2 Hubungan dengan pendekatan lain
Adapt-VQE
Algoritma ADAPT-VQE (Adaptive Derivative-Assembled Pseudo-Trotter Variational Quantum Eigensolver) adalah peningkatan dari algoritma VQE asli, yang dirancang untuk meningkatkan efisiensi, akurasi, dan skalabilitas untuk simulasi kuantum, khususnya dalam kimia kuantum.
Algoritma VQE asli yang dijelaskan sepanjang pelajaran ini menggunakan ansatz tetap yang telah ditentukan sebelumnya untuk mendekati ground state sistem. Dalam kasus kita, kita menggunakan efficient_su2, dengan satu repetisi, menggunakan gate rotasi Y dan RZ. Meskipun parameter dalam gate RZ berubah, struktur ansatz dan gate yang digunakan ini tidak berubah.
ADAPT-VQE mengatasi keterbatasan VQE melalui konstruksi ansatz adaptif. Alih-alih memulai dengan ansatz tetap, ADAPT-VQE membangun ansatz secara dinamis dan iteratif. Pada setiap langkah, ia memilih operator dari kumpulan yang telah ditentukan (seperti operator eksitasi fermionik) yang memiliki gradien terbesar terhadap energi. Ini memastikan hanya operator yang paling berdampak yang ditambahkan, menghasilkan ansatz yang kompak dan efisien[4-6]. Pendekatan ini dapat memiliki beberapa efek menguntungkan:
- Kedalaman Circuit yang Berkurang: Dengan menumbuhkan ansatz secara inkremental dan hanya fokus pada operator yang diperlukan, ADAPT-VQE meminimalkan operasi gate dibandingkan pendekatan VQE tradisional[5,7].
- Akurasi yang Ditingkatkan: Sifat adaptif memungkinkan ADAPT-VQE memulihkan lebih banyak energi korelasi di setiap langkah, membuatnya sangat efektif untuk sistem yang berkorelasi kuat di mana VQE tradisional kesulitan[8,9].
- Skalabilitas dan Ketahanan terhadap Noise: Ansatz yang kompak mengurangi akumulasi kesalahan gate, mengurangi overhead komputasi, dan membatasi jumlah parameter variasional yang harus diminimalkan.
ADAPT-VQE masih belum sempurna. Dalam beberapa kasus ia bisa terjebak atau melambat oleh minimum lokal, dan mungkin mengalami over-parameterisasi. Ia juga bisa cukup intensif sumber daya, karena memerlukan perhitungan gradien dan optimasi parameter dengan banyak struktur gate.
Estimasi fase kuantum (QPE)
QPE memiliki tujuan yang serupa dengan VQE, tapi sangat berbeda dalam implementasinya. QPE memerlukan komputer kuantum toleran kesalahan karena sirkuit kuantumnya yang umumnya sangat dalam dan tingkat koherensi tinggi yang dibutuhkannya. Begitu QPE bisa diimplementasikan, ia akan lebih presisi dari VQE. Salah satu cara mendeskripsikan perbedaannya adalah melalui presisi sebagai fungsi kedalaman Circuit. QPE mencapai presisi dengan kedalaman Circuit yang berskala sebagai [10]. VQE memerlukan sampel untuk mencapai presisi yang sama[10,11].
Krylov, SQD, QSCI, dan lainnya dalam kursus ini
VQE membantu menetapkan algoritma kuantum yang masih bergantung pada komputer klasik, bukan hanya untuk mengoperasikan komputer kuantum, tapi untuk sebagian besar algoritma. Beberapa algoritma semacam itu menjadi fokus sisa kursus ini. Di sini, kita memberikan penjelasan singkat tentang beberapa di antaranya, hanya untuk membandingkan dan mempertentangkannya dengan VQE. Mereka akan dijelaskan secara lebih rinci dalam pelajaran berikutnya.
Krylov quantum diagonalization (KQD)
Metode subruang Krylov adalah cara memproyeksikan matriks ke subruang untuk mengurangi dimensinya dan membuatnya lebih mudah dikelola, sambil mempertahankan fitur-fitur terpenting. Salah satu trik dalam metode ini adalah menghasilkan subruang yang mempertahankan fitur-fitur ini; ternyata menghasilkan subruang ini sangat terkait dengan metode yang sudah mapan di komputer kuantum yang disebut Trotterisasi.
Ada beberapa varian metode Krylov kuantum, tapi secara umum pendekatannya adalah:
- Gunakan komputer kuantum untuk menghasilkan subruang (subruang Krylov) melalui Trotterisasi
- Proyeksikan matriks yang diminati ke subruang Krylov tersebut
- Diagonalisasi Hamiltonian yang telah diproyeksikan menggunakan komputer klasik
Sampling-based quantum diagonalization (SQD)
Sampling-based quantum diagonalization (SQD) berkaitan dengan metode Krylov karena keduanya juga berusaha mengurangi dimensi matriks yang akan didiagonalisasi sambil mempertahankan fitur-fitur utama. SQD melakukan ini dengan cara berikut:
- Mulai dengan tebakan awal untuk ground state dan siapkan sistem dalam ground state tersebut.
- Gunakan Sampler untuk mengambil sampel bitstring yang membentuk state ini.
- Gunakan kumpulan state basis komputasional dari Sampler sebagai subruang tempat kamu memproyeksikan matriks yang diminati.
- Diagonalisasi matriks yang lebih kecil dan telah diproyeksikan menggunakan komputer klasik.
Ini berkaitan dengan VQE karena keduanya memanfaatkan komputasi klasik dan kuantum untuk komponen algoritma yang substansial. Keduanya juga memiliki persyaratan yang sama bahwa kita perlu menyiapkan tebakan awal atau ansatz yang baik. Tapi distribusi pekerjaan antara komputer klasik dan kuantum dalam SQD lebih mirip metode Krylov.
Faktanya, metode Krylov dan SQD baru-baru ini telah digabungkan menjadi metode sampling-based Krylov quantum diagonalization (SKQD) [12].
Quantum subspace configuration interaction
Quantum Selected Configuration Interaction (QSCI)[13] adalah algoritma yang menghasilkan ground state yang didekati dari sebuah Hamiltonian dengan mengambil sampel fungsi gelombang percobaan untuk mengidentifikasi state basis komputasional yang signifikan guna menghasilkan subruang untuk diagonalisasi klasik. Baik SQD maupun QSCI menggunakan komputer kuantum untuk membangun subruang yang dikurangi. Kekuatan tambahan QSCI ada pada preparasi state-nya, terutama dalam konteks masalah kimia. Ia memanfaatkan berbagai strategi seperti menggunakan state yang berevolusi terhadap waktu [14] dan sekumpulan ansatz yang terinspirasi kimia. Dengan fokus pada preparasi state yang efisien, QSCI mengurangi biaya komputasi kuantum untuk Hamiltonian kimia sambil mempertahankan fidelitas tinggi dan memanfaatkan ketahanan noise dari teknik pengambilan sampel state kuantum [15]. QSCI juga menyediakan teknik konstruksi adaptif yang memberikan lebih banyak ansatz untuk hasil yang lebih baik.
Alur kerja default QSCI untuk masalah kimia adalah sebagai berikut:
- Bangun Hamiltonian molekuler menggunakan perangkat lunak pilihanmu (seperti SciPy).
- Siapkan algoritma QSCI dengan memilih state awal yang tepat dan ansatz yang terinspirasi kimia dengan sekumpulan parameter yang telah dipilih sebelumnya.
- Ambil sampel state basis yang signifikan dan diagonalisasi Hamiltonian menggunakan komputer klasik untuk mendapatkan energi ground state.
- Seringkali digunakan pemulihan konfigurasi [16] dan post-seleksi simetri [15] sebagai teknik pasca-pemrosesan.
- Opsional, alur kerja adaptive QSCI memiliki loop optimasi tambahan dari langkah 2 ke langkah 3, dengan menggunakan lebih banyak ansatz dengan state awal acak.
Uji pemahamanmu
Baca pertanyaan di bawah, pikirkan jawabanmu, lalu klik segitiga untuk melihat solusinya.
Apa yang dimiliki VQE secara umum dengan semua metode lain yang tercantum di atas (kecuali QPE yang tidak dijelaskan secara rinci)?
Jawaban:
Semua melibatkan state atau fungsi gelombang percobaan. Semua bekerja paling baik ketika tebakan awal untuk state percobaan ini sangat bagus.
Jawaban yang juga benar adalah bahwa semuanya paling mudah diimplementasikan ketika Hamiltonian mudah diukur (bisa diurutkan menjadi relatif sedikit kelompok operator Pauli yang komut).
Apa yang dimiliki VQE secara khusus yang tidak dimiliki oleh metode lain yang tercantum di atas?
Jawaban:
Optimizer klasik. Tidak ada yang lain menggunakan algoritma optimasi klasik untuk memilih parameter variasional.
Referensi
[2] https://en.wikipedia.org/wiki/Variational_quantum_eigensolver
[3] https://journals.aps.org/prapplied/abstract/10.1103/PhysRevApplied.19.024047
[4] https://arxiv.org/abs/2111.05176
[6] https://inquanto.quantinuum.com/tutorials/InQ_tut_fe4n2_2.html
[7] https://www.nature.com/articles/s41467-019-10988-2
[8] https://arxiv.org/abs/2210.15438
[9] https://journals.aps.org/prresearch/abstract/10.1103/PhysRevResearch.6.013254
[10] https://arxiv.org/html/2403.09624v1
[11] https://www.nature.com/articles/s42005-023-01312-y
[13] https://arxiv.org/abs/1802.00171
[14] https://arxiv.org/abs/2103.08505
[15] https://arxiv.org/html/2501.09702v1
[16] https://quri-sdk.qunasys.com/docs/examples/quri-algo-vm/qsci/
[17] https://arxiv.org/abs/2412.13839