Diagonalisasi Krylov Kuantum
Dalam pelajaran tentang diagonalisasi Krylov kuantum (KQD) ini, kita akan menjawab pertanyaan berikut:
- Apa itu metode Krylov, secara umum?
- Kenapa metode Krylov bekerja dan dalam kondisi apa?
- Bagaimana komputasi kuantum berperan?
Bagian kuantum dari perhitungan ini sebagian besar didasarkan pada karya dalam Ref [1].
Video di bawah ini memberikan gambaran umum tentang metode Krylov dalam komputasi klasik, memotivasi penggunaannya, dan menjelaskan bagaimana komputasi kuantum dapat berperan dalam alur kerja tersebut. Teks berikutnya memberikan detail lebih lanjut dan mengimplementasikan metode Krylov secara klasik maupun menggunakan komputer kuantum.
1. Pengenalan metode Krylov
Metode subruang Krylov bisa merujuk pada salah satu dari beberapa metode yang dibangun di sekitar apa yang disebut subruang Krylov. Ulasan lengkap tentang ini berada di luar cakupan pelajaran ini, tapi Ref [2-4] semuanya bisa memberikan latar belakang yang jauh lebih banyak. Di sini, kita akan fokus pada apa itu subruang Krylov, bagaimana dan mengapa berguna dalam memecahkan masalah nilai eigen, dan akhirnya bagaimana bisa diimplementasikan pada komputer kuantum. Definisi: Diberikan matriks simetris dan semi-definit positif , ruang Krylov dari orde adalah ruang yang dibentangkan oleh vektor-vektor yang diperoleh dengan mengalikan pangkat-pangkat lebih tinggi dari matriks , hingga , dengan vektor referensi .
Meskipun vektor-vektor di atas membentangkan apa yang kita sebut subruang Krylov, tidak ada alasan untuk berasumsi bahwa mereka akan ortogonal. Kita sering menggunakan proses ortonormalisasi iteratif yang mirip dengan ortogonalisasi Gram-Schmidt. Di sini prosesnya sedikit berbeda karena setiap vektor baru dibuat ortogonal terhadap yang lain saat dihasilkan. Dalam konteks ini disebut iterasi Arnoldi. Dimulai dari vektor awal , kita menghasilkan vektor berikutnya , lalu memastikan bahwa vektor kedua ini ortogonal terhadap yang pertama dengan mengurangi proyeksinya pada . Yaitu
Sekarang mudah untuk melihat bahwa karena
Kita lakukan hal yang sama untuk vektor berikutnya, memastikannya ortogonal terhadap kedua vektor sebelumnya:
Jika kita ulangi proses ini untuk semua vektor, kita punya basis ortonormal lengkap untuk subruang Krylov. Perhatikan bahwa proses ortogonalisasi di sini akan menghasilkan nol begitu , karena vektor ortogonal tentu membentangkan ruang penuh. Proses ini juga akan menghasilkan nol jika suatu vektor merupakan vektor eigen dari karena semua vektor selanjutnya akan menjadi kelipatan dari vektor tersebut.
1.1 Contoh sederhana: Krylov dengan tangan
Mari kita telusuri pembangkitan subruang Krylov pada matriks yang sangat kecil, sehingga kita bisa melihat prosesnya. Kita mulai dengan matriks awal yang menjadi perhatian kita:
Untuk contoh kecil ini, kita dapat menentukan vektor eigen dan nilai eigen dengan mudah bahkan dengan tangan. Kita tampilkan solusi numeriknya di sini.
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit qiskit-ibm-runtime scipy sympy
# One might use linalg.eigh here, but later matrices may not be Hermitian. So we use
# linalg.eig in this lesson.
import numpy as np
A = np.array([[4, -1, 0], [-1, 4, -1], [0, -1, 4]])
eigenvalues, eigenvectors = np.linalg.eig(A)
print("The eigenvalues are ", eigenvalues)
print("The eigenvectors are ", eigenvectors)
The eigenvalues are [2.58578644 4. 5.41421356]
The eigenvectors are [[ 5.00000000e-01 -7.07106781e-01 5.00000000e-01]
[ 7.07106781e-01 1.37464400e-16 -7.07106781e-01]
[ 5.00000000e-01 7.07106781e-01 5.00000000e-01]]
Kita catat di sini untuk perbandingan nanti:
Kita ingin mempelajari bagaimana proses ini bekerja (atau gagal) seiring kita meningkatkan dimensi subruang Krylov kita, . Untuk itu, kita akan menerapkan proses ini:
- Buat subruang dari ruang vektor penuh dimulai dengan vektor yang dipilih secara acak (sebut jika sudah dinormalisasi, seperti di atas).
- Proyeksikan matriks penuh ke subruang tersebut, dan cari nilai eigen dari matriks yang diproyeksikan .
- Perbesar ukuran subruang dengan menghasilkan lebih banyak vektor, pastikan mereka ortonormal, menggunakan proses yang mirip dengan ortogonalisasi Gram-Schmidt.
- Proyeksikan ke subruang yang lebih besar dan cari nilai eigen dari matriks yang dihasilkan, .
- Ulangi ini sampai nilai eigen konvergen (atau dalam kasus mainan ini, sampai kamu telah menghasilkan vektor yang membentangkan ruang vektor penuh dari matriks asli ).
Implementasi normal dari metode Krylov tidak perlu memecahkan masalah nilai eigen untuk matriks yang diproyeksikan pada setiap subruang Krylov saat dibangun. Kamu bisa membangun subruang dengan dimensi yang diinginkan, memproyeksikan matriks ke subruang tersebut, dan mendiagonalisasi matriks yang diproyeksikan. Memproyeksikan dan mendiagonalisasi pada setiap dimensi subruang hanya dilakukan untuk memeriksa konvergensi.
Dimensi :
Kita pilih vektor acak, katakanlah
Jika belum dinormalisasi, normalisasikan.
Kita sekarang memproyeksikan matriks kita ke subruang dari satu vektor ini:
Ini adalah proyeksi matriks kita ke subruang Krylov kita ketika hanya berisi satu vektor, . Nilai eigen dari matriks ini secara trivial adalah 4. Kita bisa menganggap ini sebagai estimasi zeroth-order dari nilai eigen (dalam hal ini hanya satu) dari . Meskipun itu adalah estimasi yang buruk, itu berada dalam orde besaran yang benar.
Dimensi :
Kita sekarang menghasilkan vektor berikutnya dalam subruang kita melalui operasi dengan pada vektor sebelumnya:
Sekarang kita kurangi proyeksi vektor ini ke vektor sebelumnya untuk memastikan ortogonalitas.
Jika belum dinormalisasi, normalisasikan. Dalam hal ini, vektor sudah dinormalisasi, jadi
Kita sekarang memproyeksikan matriks A kita ke subruang dari dua vektor ini:
Kita masih dihadapkan dengan masalah menentukan nilai eigen dari matriks ini. Tapi matriks ini sedikit lebih kecil dari matriks penuh. Dalam masalah yang melibatkan matriks yang sangat besar, bekerja dengan subruang yang lebih kecil ini bisa sangat menguntungkan.
Meskipun ini masih bukan estimasi yang baik, ini lebih baik dari estimasi zeroth order. Kita akan melakukan ini satu iterasi lagi, untuk memastikan prosesnya jelas. Namun, ini meremehkan tujuan metode ini, karena kita akan berakhir mendiagonalisasi matriks 3x3 pada iterasi berikutnya, yang berarti kita belum menghemat waktu atau daya komputasi.
Dimensi :
Kita sekarang menghasilkan vektor berikutnya dalam subruang kita melalui operasi dengan A pada vektor sebelumnya:
Sekarang kita kurangi proyeksi vektor ini ke kedua vektor sebelumnya untuk memastikan ortogonalitas.
Jika belum dinormalisasi, normalisasikan. Dalam hal ini, vektor sudah dinormalisasi, jadi
Kita sekarang memproyeksikan matriks kita ke subruang dari vektor-vektor ini:
Kita sekarang menentukan nilai eigennya:
Nilai eigen ini persis dengan nilai eigen dari matriks asli . Ini harus demikian, karena kita telah memperluas subruang Krylov kita hingga membentangkan seluruh ruang vektor dari matriks asli .
Dalam contoh ini, metode Krylov mungkin tidak terlihat lebih mudah dari diagonalisasi langsung. Memang, seperti yang akan kita lihat di bagian berikutnya, metode Krylov hanya menguntungkan di atas dimensi matriks tertentu; ini dimaksudkan untuk membantu kita memecahkan masalah nilai eigen/vektor eigen dari matriks yang sangat besar.
Ini adalah satu-satunya contoh yang akan kita tunjukkan dikerjakan "dengan tangan", tapi bagian 2 di bawah menunjukkan contoh komputasional.
Klarifikasi istilah
Kesalahpahaman umum adalah bahwa hanya ada satu subruang Krylov untuk masalah tertentu. Tapi tentu saja, karena ada banyak vektor awal yang bisa diterapkan matriks kita, ada banyak subruang Krylov yang mungkin. Kita hanya akan menggunakan frasa "the Krylov subspace" untuk merujuk pada subruang Krylov tertentu yang sudah didefinisikan untuk contoh tertentu. Untuk pendekatan pemecahan masalah umum, kita akan merujuk ke "a Krylov subspace". Klarifikasi terakhir adalah bahwa valid untuk merujuk ke "Krylov space". Sering terlihat disebut "Krylov subspace" karena penggunaannya dalam konteks memproyeksikan matriks dari ruang awal ke dalam subruang. Mengikuti konteks tersebut, kita akan sebagian besar menyebutnya sebagai subruang di sini.
Periksa pemahamanmu
Baca pertanyaan di bawah ini, pikirkan jawabanmu, lalu klik segitiga untuk mengungkap setiap solusi.
Jelaskan mengapa tidak (a) berguna, dan (b) mungkin untuk memperluas dimensi subruang Krylov melampaui dimensi dari matriks yang menjadi perhatian.
Jawaban:
(a) Karena kita menortonormalisasi vektor-vektor saat kita membuatnya, sekumpulan vektor tersebut akan membentuk basis lengkap, artinya kombinasi linear dari mereka bisa digunakan untuk membuat vektor apa pun dalam ruang tersebut. (b) Proses ortogonalisasi terdiri dari mengurangi proyeksi vektor baru ke semua vektor sebelumnya. Jika semua vektor sebelumnya membentangkan ruang vektor penuh, maka mengurangi proyeksi ke subruang penuh akan selalu meninggalkan kita dengan vektor nol.
Misalkan seorang rekan peneliti sedang mendemonstrasikan metode Krylov yang diterapkan pada matriks mainan kecil untuk beberapa kolega. Rekan peneliti ini berencana menggunakan matriks dan vektor awal:
dan
Apakah ada yang salah dengan ini? Bagaimana kamu akan menyarankan kolegamu?
Jawaban:
Kolegamu secara tidak sengaja memilih vektor eigen sebagai vektor awalnya. Mengoperasikan matriks pada vektor awal hanya akan mengembalikan vektor yang sama, diskalakan oleh nilai eigen. Ini tidak akan menghasilkan subruang dengan dimensi yang bertambah. Sarankan kolegamu untuk memilih vektor awal yang berbeda, pastikan itu bukan vektor eigen.
Terapkan metode Krylov pada matriks di bawah ini, pilih vektor awal baru yang sesuai. Tuliskan estimasi nilai eigen minimum pada orde ke-0 dan ke-1 dari subruang Krylov kamu.
Jawaban:
Ada banyak kemungkinan jawaban tergantung pada pilihan vektor awal. Kita akan memilih:
Untuk mendapatkan kita terapkan sekali ke , lalu buat ortogonal terhadap
Pada orde ke-0, proyeksi ke subruang Krylov kita adalah
Pada orde ke-1, proyeksi ke subruang Krylov ini adalah
Ini bisa dilakukan dengan tangan, tapi paling mudah menggunakan numpy:
import numpy as np
vstar = np.array([[1/np.sqrt(3),1/np.sqrt(3),1/np.sqrt(3)],[-1/np.sqrt(6),np.sqrt(2/3),-1/np.sqrt(6)]]
)
A = np.array([[1, 1, 0],
[1, 1, 1],
[0, 1, 1]])
v = np.array([[1/np.sqrt(3),-1/np.sqrt(6)],[1/np.sqrt(3),np.sqrt(2/3)],[1/np.sqrt(3),-1/np.sqrt(6)]])
proj = vstar@A@v
print(proj)
eigenvalues, eigenvectors = np.linalg.eig(proj)
print("The eigenvalues are ", eigenvalues)
print("The eigenvectors are ", eigenvectors)
outputs:
[[ 2.33333333 0.47140452]
[ 0.47140452 -0.33333333]]
The eigenvalues are [ 2.41421356 -0.41421356]
The eigenvectors are [[ 0.98559856 -0.16910198]
[ 0.16910198 0.98559856]]
Estimasi nilai eigen minimum adalah -0.414.
1.2 Jenis-jenis metode Krylov
"Metode subruang Krylov" bisa merujuk pada salah satu dari beberapa teknik iteratif yang digunakan untuk memecahkan sistem linear besar dan masalah nilai eigen. Yang semuanya memiliki kesamaan adalah mereka membangun solusi perkiraan dari subruang Krylov
di mana adalah tebakan awal (lihat Ref [5]). Mereka berbeda dalam cara memilih perkiraan terbaik dari subruang ini, menyeimbangkan faktor seperti laju konvergensi, penggunaan memori, dan biaya komputasi keseluruhan. Fokus pelajaran ini adalah memanfaatkan komputasi kuantum dalam konteks metode subruang Krylov; pembahasan mendalam tentang metode-metode ini berada di luar cakupannya. Definisi singkat di bawah ini hanya untuk konteks dan mencakup beberapa referensi untuk menyelidiki metode-metode ini lebih lanjut.
Metode gradien konjugat (CG): Metode ini digunakan untuk memecahkan sistem linear simetris dan definit positif[6]. Ini meminimalkan A-norm dari galat pada setiap iterasi, membuatnya sangat efektif untuk sistem yang muncul dari PDE eliptik yang terdiskretisasi[7]. Kita akan menggunakan pendekatan ini di bagian berikutnya untuk memotivasi mengapa subruang Krylov akan menjadi subruang yang efektif untuk menyelidiki solusi yang lebih baik dari sistem linear.
Metode residual minimal tergeneralisasi (GMRES): Ini dirancang untuk memecahkan sistem linear non-simetris umum. Ini meminimalkan norma residual di atas ruang Krylov pada setiap iterasi, membuatnya kuat tapi berpotensi intensif memori untuk sistem besar[7].
Metode residual minimal (MINRES): Metode ini digunakan untuk memecahkan sistem linear indefinit simetris. Ini mirip dengan GMRES tapi memanfaatkan simetri matriks untuk mengurangi biaya komputasi[8].
Pendekatan lain yang perlu diperhatikan termasuk metode ortogonalisasi penuh (FOM), yang terkait erat dengan metode Arnoldi untuk masalah nilai eigen, metode gradien konjugat bi (BiCG), dan metode reduksi dimensi terinduksi (IDR).
1.3 Mengapa metode subruang Krylov bekerja
Di sini kita akan memotivasi bahwa metode subruang Krylov harus menjadi cara efisien untuk mendekati nilai eigen matriks melalui penyempurnaan iteratif dari aproksimasi vektor eigen, melalui lensa penurunan terjal. Kita akan berargumen bahwa diberikan tebakan awal tentang keadaan dasar, ruang koreksi berturut-turut terhadap tebakan awal yang menghasilkan konvergensi tercepat adalah subruang Krylov. Kita berhenti sebelum pembuktian konvergensi yang ketat.
Asumsikan matriks yang menjadi perhatian kita bersifat simetris dan definit positif. Ini membuat argumen kita paling relevan dengan metode CG di atas. Kita tidak membuat asumsi tentang sparsitas di sini; juga tidak mengklaim bahwa harus bersifat Hermitian (yang diperlukan jika itu adalah Hamiltonian).
Kita biasanya ingin memecahkan masalah dengan bentuk
Seseorang mungkin membayangkan bahwa di mana adalah konstanta, seperti dalam masalah nilai eigen. Tapi pernyataan masalah kita tetap lebih umum untuk saat ini.
Kita mulai dengan vektor yang merupakan solusi perkiraan. Meskipun ada paralel antara tebakan ini dan di Bagian 1.1, kita tidak memanfaatkan ini di sini. Tebakan kita memiliki galat, yang kita sebut
Kita juga mendefinisikan residual
Di sini kita menggunakan huruf kapital untuk membedakan residual dari dimensi subruang Krylov kita .

Kita sekarang ingin membuat langkah koreksi dengan bentuk
yang kita harap meningkatkan aproksimasi kita. Di sini adalah vektor yang belum ditentukan. Biarkan menjadi galat setelah koreksi dilakukan. Maka

Kita tertarik bagaimana galat kita berperilaku ketika ditransformasikan oleh matriks kita. Jadi mari kita hitung A-norm dari galatnya. Yaitu
di mana kita menggunakan simetri dan juga bahwa Di sini adalah konstanta yang tidak bergantung pada . Seperti yang disebutkan di Bagian 1.2, A-norm dari galat bukan satu-satunya kuantitas yang mungkin kita pilih untuk diminimalkan, tapi itu adalah pilihan yang baik. Kita ingin melihat bagaimana kuantitas ini bervariasi dengan pilihan vektor koreksi Jadi kita mendefinisikan fungsi dengan menetapkan
hanyalah galat sebagai fungsi dari koreksi yang diukur dalam A-norm. Oleh karena itu, kita ingin memilih sedemikian rupa sehingga sekecil mungkin. Untuk tujuan ini, kita hitung gradien dari . Menggunakan simetri kita punya
Gradien menunjuk ke arah pendakian terjal, artinya kebalikannya memberi kita arah di mana fungsi paling banyak berkurang: arah penurunan terjal. Pada tebakan awal kita , di mana , kita punya bahwa Jadi, fungsi paling banyak berkurang ke arah residual Dengan demikian, pilihan awal kita akan paling banyak mendapat manfaat dari penambahan vektor untuk beberapa skalar .
Pada langkah berikutnya, kita memilih, lagi, vektor dan menambahkan nilainya ke aproksimasi saat ini. Menggunakan argumen yang sama seperti sebelumnya kita pilih untuk beberapa skalar . Kita teruskan dengan cara ini, sehingga iterasi ke- dari vektor kita adalah
Setara dengan itu, kita ingin membangun ruang dari mana kita memilih estimasi yang lebih baik dengan menambahkan , , dan seterusnya, berurutan. Vektor yang diestimasi ke- berada dalam
Sekarang, menggunakan relasi bahwa
kita lihat bahwa
Artinya, ruang yang kita bangun yang paling efisien mendekati solusi yang benar adalah persis ruang yang dibangun oleh operasi berturut-turut matriks pada Subruang Krylov adalah ruang yang dibentangkan oleh vektor-vektor dari arah penurunan terjal yang berturut-turut.
Akhirnya kita tekankan lagi bahwa kita tidak membuat klaim numerik tentang penskalaan pendekatan ini, juga tidak membahas manfaat komparatif untuk matriks jarang. Ini hanya dimaksudkan untuk memotivasi penggunaan metode subruang Krylov, dan menambahkan rasa intuitif untuk mereka. Kita sekarang akan mengeksplorasi perilaku metode-metode ini secara numerik.
Periksa pemahamanmu
Baca pertanyaan di bawah ini, pikirkan jawabanmu, lalu klik segitiga untuk mengungkap solusinya.
Dalam alur kerja di atas, kita mengusulkan meminimalkan A-norm dari galat. Kuantitas lain apa yang mungkin seseorang pertimbangkan untuk diminimalkan dalam mencari keadaan dasar dan nilai eigennya?
Jawaban:
Seseorang bisa membayangkan menggunakan vektor residual alih-alih A-norm dari galat. Mungkin ada kasus di mana mempertimbangkan vektor galat itu sendiri berguna.
2. Metode Krylov dalam komputasi klasik
Dalam bagian ini kita mengimplementasikan iterasi Arnoldi secara komputasional sehingga kita dapat memanfaatkan subruang Krylov dalam memecahkan masalah nilai eigen. Kita akan menerapkan ini pertama pada contoh skala kecil, kemudian memeriksa bagaimana waktu komputasi menskalakan seiring bertambahnya ukuran matriks yang menjadi perhatian. Ide kunci di sini adalah bahwa pembangkitan vektor-vektor yang membentangkan ruang Krylov akan menjadi kontributor besar terhadap total waktu komputasi yang diperlukan. Memori yang diperlukan akan bervariasi di antara metode Krylov tertentu. Tapi batasan memori dapat membatasi penggunaan metode Krylov tradisional.
2.1 Contoh sederhana skala kecil
Dalam proses membuat subruang Krylov, kita perlu menortonormalisasi vektor-vektor dalam subruang kita. Mari kita definisikan fungsi yang mengambil vektor yang sudah ada dari subruang kita vknown (tidak diasumsikan dinormalisasi) dan vektor kandidat untuk ditambahkan ke subruang kita vnext dan membuat vnext ortogonal terhadap vknown dan dinormalisasi. Mari kita selanjutnya mendefinisikan fungsi yang melangkah melalui proses ini untuk semua vektor yang sudah ada dalam subruang Krylov kita untuk memastikan set ortonormal penuh.
# vknown is some established vector in our subspace. vnext is one we wish to add,
# which must be orthogonal to vknown.
def orthog_pair(vknown, vnext):
vknown = vknown / np.sqrt(vknown.T @ vknown)
diffvec = vknown.T @ vnext * vknown
vnext = vnext - diffvec
return vnext
# v is the candidate vector to be added to our subspace. s is the existing subspace.
def orthoset(v, s):
v = v / np.sqrt(v.T @ v)
temp = v
for i in range(len(s)):
temp = orthog_pair(s[i], temp)
v = temp / np.sqrt(temp.T @ temp)
return v
Sekarang mari kita mendefinisikan fungsi yang membangun subruang Krylov yang semakin besar secara iteratif, sampai ruang vektor Krylov membentangkan ruang penuh dari matriks asli. Ini akan memungkinkan kita melihat seberapa baik nilai eigen yang diperoleh menggunakan metode subruang Krylov kita cocok dengan nilai eksak, sebagai fungsi dari dimensi subruang Krylov. Yang penting, fungsi kita krylov_full_build mengembalikan vektor Krylov, Hamiltonian yang diproyeksikan, nilai eigen, dan waktu yang diperlukan.
# Necessary imports and definitions to track time in microseconds
import time
def time_mus():
return int(time.time() * 1000000)
# This function constructs a Krylov subspace that spans the whole space of the original matrix.
# Input:
# v0 : initial vector
# matrix : original matrix to be diagonalized
# Output:
# ks : Krylov vectors
# Hs : projected Hamiltonians
# eigs : eigenvalues
# k_tot_times : time required for the operation
def krylov_full_build(v0, matrix):
t0 = time_mus()
b = v0 / np.sqrt(v0 @ v0.T)
A = matrix
ks = []
ks.append(b)
Hs = []
eigs = []
Hs.append(b.T @ A @ b)
eigs.append(np.array([b.T @ A @ b]))
k_tot_times = []
for j in range(len(A) - 1):
vec = A @ ks[j].T
ortho = orthoset(vec, ks)
ks.append(ortho)
ksarray = np.array(ks)
Hs.append(ksarray @ A @ ksarray.T)
eigs.append(np.linalg.eig(Hs[j + 1]).eigenvalues)
k_tot_times.append(time_mus() - t0)
# Return the Krylov vectors, the projected Hamiltonians, the eigenvalues,
# and the total time required.
return (ks, Hs, eigs, k_tot_times)
Kita akan menguji ini pada matriks yang masih cukup kecil, tapi lebih besar dari yang ingin kita lakukan dengan tangan.
# Define our small test matrix
test_matrix = np.array(
[
[4, -1, 0, 1, 0],
[-1, 4, -1, 2, 1],
[0, -1, 4, 3, 3],
[1, 2, 3, 4, 0],
[0, 1, 3, 0, 4],
]
)
# Give the test matrix and an initial guess as arguments in the function defined above.
# Calculate outputs.
test_ks, test_Hs, test_eigs, text_k_tot_times = krylov_full_build(
np.array([0.5, 0.5, 0, 0.5, 0.5]), test_matrix
)
Kita bisa memeriksa fungsi kita dengan memastikan bahwa pada langkah terakhir (ketika ruang Krylov adalah ruang vektor penuh dari matriks asli) nilai eigen dari metode Krylov persis sama dengan diagonalisasi numerik eksak:
print(np.linalg.eig(test_matrix).eigenvalues)
print(test_eigs[len(test_matrix) - 1])
[-1.36956923 8.43756009 2.9040308 5.34436028 4.68361806]
[-1.36956923 8.43756009 2.9040308 4.68361806 5.34436028]
Itu berhasil. Tentu saja, yang benar-benar penting adalah seberapa baik aproksimasi kita sebagai fungsi dari dimensi subruang Krylov kita. Karena kita sering peduli dengan menemukan keadaan dasar dan nilai eigen minimum lainnya (dan karena alasan aljabar lain yang dijelaskan di bawah), mari kita lihat estimasi nilai eigen terendah sebagai fungsi dari dimensi subruang Krylov. Yaitu
def errors(matrix, krylov_eigs):
targ_min = min(np.linalg.eig(matrix).eigenvalues)
err = []
for i in range(len(matrix)):
err.append(min(krylov_eigs[i]) - targ_min)
return err
import matplotlib.pyplot as plt
krylov_error = errors(test_matrix, test_eigs)
plt.plot(krylov_error)
plt.axhline(y=0, color="red", linestyle="--") # Add dashed red line at y=0
plt.xlabel("Order of Krylov subspace") # Add x-axis label
plt.ylabel("Error in minimum eigenvalue") # Add y-axis label
plt.show()
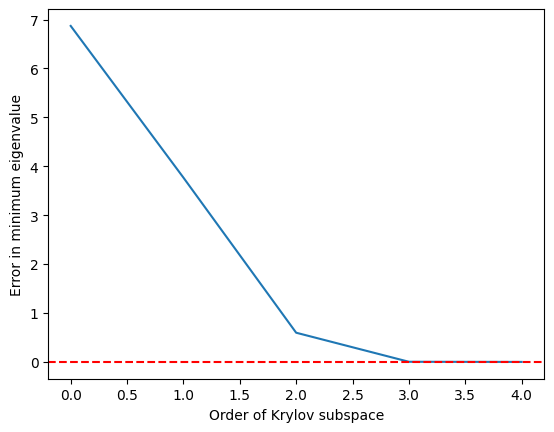
Kita lihat bahwa nilai eigen minimum tercapai dengan cukup akurat begitu subruang Krylov tumbuh ke dan sempurna pada
2.2 Penskalaan waktu dengan dimensi matriks
Mari kita yakinkan diri bahwa metode Krylov bisa menguntungkan dibanding penyelesai nilai eigen numerik eksak dengan cara berikut:
- Buat matriks acak (tidak jarang, bukan aplikasi ideal untuk KQD)
- Tentukan nilai eigen menggunakan dua metode: langsung menggunakan NumPy dan menggunakan subruang Krylov.
- Kita pilih batas untuk seberapa presisi nilai eigen kita harus, sebelum kita menerima estimasi Krylov.
- Bandingkan waktu dinding yang diperlukan untuk menyelesaikan dengan dua cara ini.
Peringatan: Seperti yang akan kita bahas secara detail di bawah, diagonalisasi Krylov kuantum paling baik diterapkan pada operator yang representasi matriksnya jarang dan/atau dapat ditulis menggunakan sejumlah kecil kelompok operator Pauli yang komuting. Matriks acak yang kita gunakan di sini tidak cocok dengan deskripsi itu. Ini hanya berguna dalam menyelidiki skala di mana metode Krylov klasik mungkin berguna. Kedua, dalam menggunakan metode Krylov kita akan menghitung nilai eigen menggunakan banyak subruang Krylov berukuran berbeda. Kita akan melaporkan waktu yang diperlukan untuk subruang dimensi minimum yang mencapai akurasi yang diperlukan untuk nilai eigen keadaan dasar. Sekali lagi, ini sedikit berbeda dari memecahkan masalah yang tidak dapat diselesaikan oleh penyelesai nilai eigen eksak, karena kita menggunakan solusi eksak untuk menilai dimensi yang diperlukan.
Kita mulai dengan menghasilkan set matriks acak kita.
import numpy as np
# Set the random seed
np.random.seed(42)
# how many random matrices will we make
num_matrix = 200
matrices = []
for m in range(1, num_matrix):
matrices.append(np.random.rand(m, m))
Kita sekarang mendiagonalisasi setiap matriks secara langsung, menggunakan numpy. Kita menghitung waktu yang diperlukan untuk diagonalisasi untuk perbandingan nanti.
matrix_numpy_times = []
matrix_numpy_eigs = []
for mm in range(num_matrix - 1):
t0 = time_mus()
matrix_numpy_eigs.append(min(np.linalg.eig(matrices[mm]).eigenvalues))
matrix_numpy_times.append(time_mus() - t0)
plt.plot(matrix_numpy_times)
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (microsec)") # Add y-axis label
plt.show()
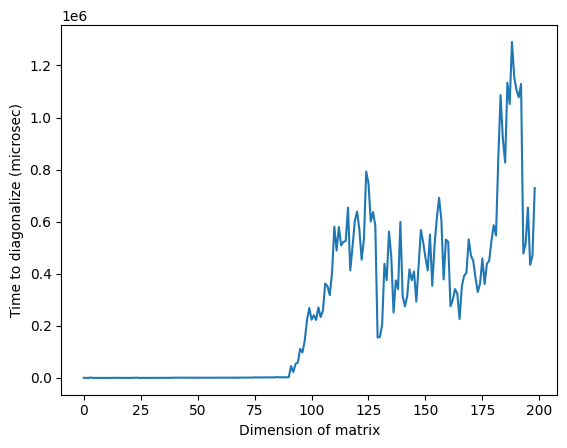
Perhatikan bahwa dalam gambar di atas, waktu yang sangat tinggi di sekitar dimensi 125 mungkin disebabkan oleh sifat acak matriks atau karena implementasi pada prosesor klasik yang digunakan, tapi itu tidak dapat direproduksi. Menjalankan ulang kode akan menghasilkan profil yang berbeda dengan puncak anomali yang berbeda.
Sekarang untuk setiap matriks kita akan membangun subruang Krylov dan menghitung nilai eigen secara bertahap. Pada setiap langkah, kita akan memeriksa apakah nilai eigen terendah telah diperoleh dalam galat absolut yang ditentukan. Subruang yang pertama kali memberi kita nilai eigen dalam galat yang ditentukan adalah subruang yang akan kita catat waktu komputasinya. Mengeksekusi sel ini mungkin memakan beberapa menit, tergantung pada kecepatan prosesor. Jangan ragu untuk melewati evaluasi atau mengurangi dimensi maksimum matriks yang didiagonalisasi. Melihat hasil yang telah dihitung sebelumnya sudah cukup.
# Choose the absolute error you can tolerate, and make a list for tracking the Krylov subspace size
# at which that error is achieved.
abserr = 0.05
accept_subspace_size = []
# Lists to store total time spent on the Krylov method, and the subset of that time spent on
# diagonalizing the projected matrix.
matrix_krylov_tot_times = []
matrix_krylov_dim = []
# Step through all our random matrices
for mm in range(0, num_matrix - 1):
test_ks, test_Hs, test_eigs, test_k_tot_times = krylov_full_build(
np.ones(len(matrices[mm])), matrices[mm]
)
# We have not yet found a Krylov subspace that produces our minimum eigenvalue to
# within the required error.
found = 0
for j in range(0, len(matrices[mm]) - 1):
# If we still haven't found the desired subspace...
if found == 0:
# ...but if this one satisfies the requirement, then record everything
if (
abs((min(test_eigs[j]) - matrix_numpy_eigs[mm]) / matrix_numpy_eigs[mm])
< abserr
):
accept_subspace_size.append(j)
matrix_krylov_tot_times.append(test_k_tot_times[j])
matrix_krylov_dim.append(mm)
found = 1
Mari kita plot waktu yang kita peroleh untuk dua metode ini untuk perbandingan:
plt.plot(matrix_numpy_times, color="blue")
plt.plot(matrix_krylov_dim, matrix_krylov_tot_times, color="green")
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (microsec)") # Add y-axis label
plt.show()

Ini adalah waktu aktual yang diperlukan, tapi untuk keperluan diskusi, mari kita haluskan kurva-kurva ini dengan merata-ratakan beberapa titik/dimensi matriks yang berdekatan. Ini dilakukan di bawah:
smooth_numpy_times = []
smooth_krylov_times = []
# Choose the number of adjacent points over which to average forward;
# the same will be used backward.
smooth_steps = 10
# We will do this smoothing for all points/matrix dimensions
for i in range(len(matrix_krylov_tot_times)):
# Ensure we don't exceed the boundaries of our lists
start = max(0, i - smooth_steps)
end = min(len(matrix_krylov_tot_times) - 1, i + smooth_steps)
# Dummy variables for accumulating an average over adjacent points. This is done for both Krylov
# and the NumPy calculations.
smooth_count = 0
smooth_numpy_sum = 0
smooth_krylov_sum = 0
for j in range(start, end):
smooth_numpy_sum = smooth_numpy_sum + matrix_numpy_times[j]
smooth_krylov_sum = smooth_krylov_sum + matrix_krylov_tot_times[j]
smooth_count = smooth_count + 1
# Appending the averaged adjacent values to our new smooth lists
smooth_numpy_times.append(smooth_numpy_sum / smooth_count)
smooth_krylov_times.append(smooth_krylov_sum / smooth_count)
plt.plot(smooth_numpy_times, color="blue")
plt.plot(smooth_krylov_times, color="green")
plt.xlabel("Dimension of matrix") # Add x-axis label
plt.ylabel("Time to diagonalize (smoothed, microsec)") # Add y-axis label
plt.show()

Perhatikan bahwa waktu yang diperlukan untuk membangun subruang Krylov awalnya melebihi waktu yang diperlukan untuk diagonalisasi penuh numpy. Tapi seiring ukuran matriks bertambah, metode Krylov menjadi lebih menguntungkan. Ini benar bahkan jika kita menurunkan galat yang dapat diterima, tapi keuntungan tersebut mulai pada ukuran matriks yang lebih besar. Ini layak untuk dianalisis lebih lanjut.
Kompleksitas waktu dari diagonalisasi numerik adalah (dengan beberapa variasi di antara algoritma). Kompleksitas waktu dari menghasilkan basis ortonormal dari vektor juga . Jadi keuntungan dari metode Krylov tidak terkait dengan penggunaan basis ortonormal, tapi dengan penggunaan basis ortonormal tertentu yang secara efektif memilih nilai eigen yang menjadi perhatian. Kita sudah melihat ini dari sketsa bukti di bagian pertama pelajaran ini, dan ini sangat penting untuk jaminan konvergensi dalam metode Krylov. Mari kita tinjau kemajuan kita sejauh ini:
- Untuk matriks yang sangat besar, metode subruang Krylov mungkin menghasilkan nilai eigen perkiraan dalam toleransi yang diperlukan lebih cepat dari algoritma diagonalisasi tradisional.
- Untuk matriks yang sangat besar tersebut, pembangkitan subruang Krylov adalah bagian yang paling memakan waktu dari metode subruang Krylov.
- Dengan demikian cara yang efisien untuk menghasilkan subruang Krylov akan sangat berharga. Inilah akhirnya di mana komputer kuantum masuk ke dalam gambar.
Periksa pemahamanmu
Baca pertanyaan di bawah ini, pikirkan jawabanmu, lalu klik segitiga untuk mengungkap solusinya.
Lihat plot yang dihaluskan dari waktu diagonalisasi vs. dimensi matriks di atas.
(a) Pada dimensi matriks berapa kira-kira metode Krylov menjadi lebih cepat, menurut plot ini?
(b) Aspek apa dari perhitungan yang bisa mengubah dimensi di mana metode Krylov menjadi lebih cepat?
Jawaban:
(a) Jawaban mungkin bervariasi jika kamu menjalankan ulang perhitungan, tapi metode Krylov menjadi lebih cepat pada sekitar dimensi 80-85. (b) Ada banyak kemungkinan jawaban. Beberapa faktor penting adalah presisi yang kita butuhkan dan sparsitas dari matriks yang didiagonalisasi.
3. Krylov via evolusi waktu
Semua yang sudah kita bahas sejauh ini bisa dilakukan secara klasik. Jadi, kapan dan bagaimana kita menggunakan komputer kuantum? Untuk matriks yang sangat besar, metode Krylov bisa membutuhkan waktu komputasi yang lama dan memori yang besar. Waktu yang dibutuhkan untuk operasi matriks pada skalanya adalah di kasus terburuk. Bahkan perkalian matriks sparse pada sebuah vektor (kasus umum untuk solver Krylov klasik) punya kompleksitas waktu yang skalanya seperti . Ini dilakukan untuk setiap vektor yang kita inginkan dalam subruang kita. Dimensi subruang biasanya bukan pecahan yang signifikan dari , dan sering skalanya seperti . Jadi menghasilkan semua vektor skalanya seperti di kasus terburuk. Meskipun ada langkah-langkah lain seperti ortogonalisasi, ini adalah skala dominan yang perlu diingat.
Komputasi kuantum memungkinkan kita mengubah atribut masalah mana yang menentukan skala waktu dan sumber daya yang dibutuhkan. Alih-alih ketergantungan pada ukuran matriks di semua aspek, kita akan melihat hal-hal seperti jumlah shot dan jumlah suku Pauli yang tidak komuting yang menyusun Hamiltonian. Mari kita jelajahi cara kerjanya.
3.1 Evolusi waktu
Ingat bahwa operator yang mengevolusi waktu sebuah keadaan kuantum adalah (dan sangat umum, terutama dalam komputasi kuantum, untuk menghilangkan dari notasi). Salah satu cara memahami dan bahkan mewujudkan fungsi eksponensial dari sebuah operator adalah dengan melihat ekspansi deret Taylornya. Perhatikan bahwa operasi ini yang bekerja pada beberapa vektor awal menghasilkan jumlah suku-suku dengan pangkat yang meningkat yang diterapkan pada keadaan awal. Sepertinya kita bisa membangun subruang Krylov kita hanya dengan mengevolusi waktu keadaan tebakan awal!
Kendalanya ada pada realisasi evolusi waktu di komputer kuantum nyata. Banyak suku dalam Hamiltonian yang tidak akan komuting satu sama lain. Jadi sementara beberapa operator eksponensial sederhana seperti berhubungan dengan Circuit sederhana, Hamiltonian umum tidak demikian. Dan karena mengandung suku-suku yang tidak komuting, kita tidak bisa begitu saja menguraikan eksponensial menjadi perkalian eksponensial-eksponensial sederhana, seperti yang bisa kita lakukan dengan bilangan.
Jadi ini tidak sederhana, tapi ini adalah proses yang sudah banyak dipelajari dalam komputasi kuantum. Kita melakukan evolusi waktu pada komputer kuantum menggunakan proses yang disebut trotterisasi, yang sendirinya merupakan subjek yang kaya[10]. Tapi secara garis besar, dengan memecah evolusi waktu menjadi langkah-langkah yang sangat kecil, katakanlah langkah berukuran , kita membatasi efek dari non-komutativitas suku-suku.
di mana .
Mari kita sebut subruang Krylov berorde r yang kita hasilkan dalam konteks klasik menggunakan pangkat H secara langsung sebagai "subruang Krylov pangkat".
Sekarang kita menghasilkan ruang serupa menggunakan operator evolusi waktu uniter ; kita akan menyebutnya "ruang Krylov uniter" . Subruang Krylov pangkat yang kita gunakan secara klasik tidak bisa dihasilkan secara langsung di komputer kuantum karena bukan operator uniter. Menggunakan subruang Krylov uniter dapat ditunjukkan memberikan jaminan konvergensi yang serupa dengan subruang Krylov pangkat, yaitu, kesalahan keadaan dasar konvergen secara efisien selama keadaan awal memiliki tumpang tindih dengan keadaan dasar sejati yang tidak berkurang secara eksponensial, dan selama ada celah yang cukup antar nilai eigen. Lihat Ref [1] untuk diskusi konvergensi yang lebih tepat.
Di sini, pangkat-pangkat menjadi langkah waktu yang berbeda (pangkat dari adalah melangkah maju sebesar waktu ). Kita bisa memberi label pada elemen subruang yang dievolusilkan waktu selama total waktu sebagai .
Kita bisa memproyeksikan Hamiltonian H kita ke subruang Krylov uniter, . Dengan kata lain, kita menghitung setiap elemen matriks dalam basis . Kita akan menyebut matriks yang diproyeksikan ini sebagai .
3.2 Cara implementasi di komputer kuantum
Elemen-elemen matriks dari diberikan oleh nilai ekspektasi , yang bisa diestimasi menggunakan komputer kuantum. Ingat bahwa bisa ditulis sebagai jumlah operator Pauli pada qubit-qubit berbeda, dan tidak semua operator Pauli bisa diukur secara bersamaan. Kita bisa mengelompokkan suku-suku Pauli menjadi grup-grup suku yang komuting, dan mengukur semuanya sekaligus. Tapi kita mungkin membutuhkan banyak grup seperti itu untuk mencakup semua suku. Jadi jumlah grup komuting berbeda yang bisa membagi suku-suku tersebut, , menjadi penting.
Di sini adalah string Pauli berbentuk atau sekumpulan string Pauli seperti itu yang saling komuting. Mengingat kita bisa menulis sebagai jumlah operator-operator yang bisa diukur, ekspresi berikut untuk elemen matriks dari bisa direalisasikan menggunakan primitif Estimator Qiskit Runtime.
Di mana adalah vektor-vektor ruang Krylov uniter dan adalah kelipatan langkah waktu yang dipilih. Di komputer kuantum, perhitungan setiap elemen matriks bisa dilakukan dengan algoritma apapun yang memungkinkan kita memperoleh tumpang tindih antar keadaan kuantum. Dalam pelajaran ini kita akan fokus pada uji Hadamard. Mengingat memiliki dimensi , Hamiltonian yang diproyeksikan ke subruang akan memiliki dimensi . Dengan yang cukup kecil (umumnya sudah cukup untuk mendapatkan konvergensi estimasi nilai eigen) kita kemudian bisa dengan mudah mendiagonalisasi Hamiltonian yang diproyeksikan secara klasik. Namun, kita tidak bisa langsung mendiagonalisasi karena non-ortogonalitas vektor-vektor ruang Krylov. Kita harus mengukur tumpang tindih mereka dan membangun matriks
Ini memungkinkan kita memecahkan masalah nilai eigen dalam ruang non-ortonormal (juga disebut masalah nilai eigen terampat)
Seseorang kemudian bisa mendapatkan estimasi nilai eigen dan keadaan eigen dari dengan melihat solusi masalah nilai eigen terampat ini. Misalnya, estimasi energi keadaan dasar diperoleh dengan mengambil nilai eigen terkecil dan keadaan dasar dari eigenvector yang bersesuaian. Koefisien dalam menentukan kontribusi dari vektor-vektor berbeda yang merentang .
Masalah nilai eigen terampat
Mengapa kita tidak bisa begitu saja mendiagonalisasi ? Karena mengandung informasi tentang geometri basis Krylov (yang non-ortogonal dalam semua kasus kecuali kasus yang sangat khusus), sendiri tidak mendeskripsikan proyeksi dari Hamiltonian penuh, sehingga nilai eigennya tidak memiliki hubungan khusus dengan Hamiltonian penuh -- mereka bisa berupa nilai-nilai acak. Memecahkan masalah nilai eigen terampat diperlukan untuk mendapatkan nilai eigen dan eigenvector perkiraan yang berhubungan dengan proyeksi Hamiltonian penuh ke ruang Krylov.
Gambar ini menunjukkan representasi Circuit dari uji Hadamard yang dimodifikasi, sebuah metode yang digunakan untuk menghitung tumpang tindih antara berbagai keadaan kuantum. Untuk setiap elemen matriks , sebuah uji Hadamard antara keadaan , dilakukan. Ini disorot dalam gambar dengan skema warna untuk elemen matriks dan operasi , yang bersesuaian. Jadi, serangkaian uji Hadamard untuk semua kombinasi yang mungkin dari vektor ruang Krylov diperlukan untuk menghitung semua elemen matriks dari Hamiltonian yang diproyeksikan . Kabel atas dalam Circuit uji Hadamard adalah qubit ancilla yang diukur baik dalam basis X atau Y, nilai ekspektasinya menentukan nilai tumpang tindih antara keadaan-keadaan. Kabel bawah mewakili semua qubit dari sistem Hamiltonian. Operasi mempersiapkan qubit sistem dalam keadaan yang dikontrol oleh keadaan qubit ancilla (demikian pula untuk ) dan operasi mewakili dekomposisi Pauli dari sistem Hamiltonian . Implementasi ini pada komputer kuantum ditunjukkan lebih detail di bawah.
4. Diagonalisasi kuantum Krylov pada komputer kuantum
Kita sekarang akan mengimplementasikan diagonalisasi kuantum Krylov pada komputer kuantum nyata. Mari mulai dengan mengimpor beberapa paket yang berguna.
import numpy as np
import scipy as sp
import matplotlib.pylab as plt
from typing import Union, List
import warnings
from qiskit.quantum_info import SparsePauliOp, Pauli
from qiskit.circuit import Parameter
from qiskit import QuantumCircuit, QuantumRegister
from qiskit.circuit.library import PauliEvolutionGate
from qiskit.synthesis import LieTrotter
# from qiskit.providers.fake_provider import Fake20QV1
from qiskit_ibm_runtime import QiskitRuntimeService, EstimatorV2 as Estimator, Batch
import itertools as it
warnings.filterwarnings("ignore")
Kita mendefinisikan fungsi di bawah ini untuk memecahkan masalah nilai eigen terampat yang baru saja kita jelaskan.
def solve_regularized_gen_eig(
h: np.ndarray,
s: np.ndarray,
threshold: float,
k: int = 1,
return_dimn: bool = False,
) -> Union[float, List[float]]:
"""
Method for solving the generalized eigenvalue problem with regularization
Args:
h (numpy.ndarray):
The effective representation of the matrix in our Krylov subspace
s (numpy.ndarray):
The matrix of overlaps between vectors of our Krylov subspace
threshold (float):
Cut-off value for the eigenvalue of s
k (int):
Number of eigenvalues to return
return_dimn (bool):
Whether to return the size of the regularized subspace
Returns:
lowest k-eigenvalue(s) that are the solution of the regularized generalized eigenvalue problem
"""
s_vals, s_vecs = sp.linalg.eigh(s)
s_vecs = s_vecs.T
good_vecs = np.array([vec for val, vec in zip(s_vals, s_vecs) if val > threshold])
h_reg = good_vecs.conj() @ h @ good_vecs.T
s_reg = good_vecs.conj() @ s @ good_vecs.T
if k == 1:
if return_dimn:
return sp.linalg.eigh(h_reg, s_reg)[0][0], len(good_vecs)
else:
return sp.linalg.eigh(h_reg, s_reg)[0][0]
else:
if return_dimn:
return sp.linalg.eigh(h_reg, s_reg)[0][:k], len(good_vecs)
else:
return sp.linalg.eigh(h_reg, s_reg)[0][:k]
Setidaknya dalam benchmarking awal, ada baiknya mengetahui solusi klasik yang tepat untuk memeriksa perilaku konvergensi. Fungsi di bawah ini menghitung energi keadaan dasar dari sebuah Hamiltonian, menggunakan Hamiltonian dan jumlah qubit sebagai argumen.
def single_particle_gs(H_op, n_qubits):
"""
Find the ground state of the single particle(excitation) sector
"""
H_x = []
for p, coeff in H_op.to_list():
H_x.append(set([i for i, v in enumerate(Pauli(p).x) if v]))
H_z = []
for p, coeff in H_op.to_list():
H_z.append(set([i for i, v in enumerate(Pauli(p).z) if v]))
H_c = H_op.coeffs
print("n_sys_qubits", n_qubits)
n_exc = 1
sub_dimn = int(sp.special.comb(n_qubits + 1, n_exc))
print("n_exc", n_exc, ", subspace dimension", sub_dimn)
few_particle_H = np.zeros((sub_dimn, sub_dimn), dtype=complex)
sparse_vecs = [
set(vec) for vec in it.combinations(range(n_qubits + 1), r=n_exc)
] # list all of the possible sets of n_exc indices of 1s in n_exc-particle states
m = 0
for i, i_set in enumerate(sparse_vecs):
for j, j_set in enumerate(sparse_vecs):
m += 1
if len(i_set.symmetric_difference(j_set)) <= 2:
for p_x, p_z, coeff in zip(H_x, H_z, H_c):
if i_set.symmetric_difference(j_set) == p_x:
sgn = ((-1j) ** len(p_x.intersection(p_z))) * (
(-1) ** len(i_set.intersection(p_z))
)
else:
sgn = 0
few_particle_H[i, j] += sgn * coeff
gs_en = min(np.linalg.eigvalsh(few_particle_H))
print("single particle ground state energy: ", gs_en)
return gs_en
4.1 Langkah 1: Petakan masalah ke Circuit kuantum dan operator
Sekarang kita akan mendefinisikan sebuah Hamiltonian. Ini berbeda dari fungsi di atas karena fungsi di atas mengambil sebuah Hamiltonian sebagai argumen dan hanya mengembalikan keadaan dasar, dan dilakukan secara klasik. Hamiltonian yang kita definisikan di sini menentukan tingkat energi semua keadaan eigen energi, dan Hamiltonian ini bisa dibangun menggunakan operator Pauli dan diimplementasikan di komputer kuantum.
Kita memilih Hamiltonian yang bersesuaian dengan rantai spin yang bisa memiliki orientasi apa pun dalam ruang, yang disebut "rantai Heisenberg". Kita mengasumsikan bahwa spin ke- bisa dipengaruhi oleh tetangga terdekatnya (spin ke- dan ke-) tetapi tidak oleh tetangga yang lebih jauh. Kita juga memungkinkan kemungkinan bahwa interaksi antar spin berbeda ketika spin menunjuk ke arah sumbu yang berbeda. Asimetri ini kadang-kadang muncul, misalnya, karena struktur kisi kristal tempat spin tertanam.
# Define problem Hamiltonian.
n_qubits = 10
# coupling strength for XX, YY, and ZZ interactions
JX = 1
JY = 3
JZ = 2
# Define the Hamiltonian:
H_int = [["I"] * n_qubits for _ in range(3 * (n_qubits - 1))]
for i in range(n_qubits - 1):
H_int[i][i] = "Z"
H_int[i][i + 1] = "Z"
for i in range(n_qubits - 1):
H_int[n_qubits - 1 + i][i] = "X"
H_int[n_qubits - 1 + i][i + 1] = "X"
for i in range(n_qubits - 1):
H_int[2 * (n_qubits - 1) + i][i] = "Y"
H_int[2 * (n_qubits - 1) + i][i + 1] = "Y"
H_int = ["".join(term) for term in H_int]
H_tot = [
(term, JZ)
if term.count("Z") == 2
else (term, JY)
if term.count("Y") == 2
else (term, JX)
for term in H_int
]
# Get operator
H_op = SparsePauliOp.from_list(H_tot)
print(H_tot)
[('ZZIIIIIIII', 2), ('IZZIIIIIII', 2), ('IIZZIIIIII', 2), ('IIIZZIIIII', 2), ('IIIIZZIIII', 2), ('IIIIIZZIII', 2), ('IIIIIIZZII', 2), ('IIIIIIIZZI', 2), ('IIIIIIIIZZ', 2), ('XXIIIIIIII', 1), ('IXXIIIIIII', 1), ('IIXXIIIIII', 1), ('IIIXXIIIII', 1), ('IIIIXXIIII', 1), ('IIIIIXXIII', 1), ('IIIIIIXXII', 1), ('IIIIIIIXXI', 1), ('IIIIIIIIXX', 1), ('YYIIIIIIII', 3), ('IYYIIIIIII', 3), ('IIYYIIIIII', 3), ('IIIYYIIIII', 3), ('IIIIYYIIII', 3), ('IIIIIYYIII', 3), ('IIIIIIYYII', 3), ('IIIIIIIYYI', 3), ('IIIIIIIIYY', 3)]
Kode di bawah ini membatasi Hamiltonian ke keadaan partikel tunggal, dan menggunakan norma spektral untuk menetapkan ukuran yang baik untuk langkah waktu kita. Kita secara heuristik memilih nilai untuk langkah waktu dt (berdasarkan batas atas norma Hamiltonian). Ref [9] menunjukkan bahwa langkah waktu yang cukup kecil adalah , dan bahwa lebih baik sampai suatu titik untuk meremehkan nilai ini daripada melebihinya, karena melebihkan nilai dapat memungkinkan kontribusi dari keadaan berenergi tinggi untuk mengkontaminasi bahkan keadaan optimal dalam ruang Krylov. Di sisi lain, memilih yang terlalu kecil menyebabkan pengkondisian subruang Krylov yang lebih buruk, karena vektor-vektor basis Krylov berbeda lebih sedikit dari satu langkah waktu ke langkah waktu berikutnya.
# Get Hamiltonian restricted to single-particle states
single_particle_H = np.zeros((n_qubits, n_qubits))
for i in range(n_qubits):
for j in range(i + 1):
for p, coeff in H_op.to_list():
p_x = Pauli(p).x
p_z = Pauli(p).z
if all(p_x[k] == ((i == k) + (j == k)) % 2 for k in range(n_qubits)):
sgn = ((-1j) ** sum(p_z[k] and p_x[k] for k in range(n_qubits))) * (
(-1) ** p_z[i]
)
else:
sgn = 0
single_particle_H[i, j] += sgn * coeff
for i in range(n_qubits):
for j in range(i + 1, n_qubits):
single_particle_H[i, j] = np.conj(single_particle_H[j, i])
# Set dt according to spectral norm
dt = np.pi / np.linalg.norm(single_particle_H, ord=2)
dt
np.float64(0.17453292519943295)
Mari kita tentukan dimensi Krylov maksimum yang ingin kita gunakan, meskipun kita akan memeriksa konvergensi pada dimensi yang lebih kecil. Kita juga menentukan jumlah langkah Trotter yang digunakan dalam evolusi waktu. Untuk keperluan pelajaran ini, kita akan memilih dimensi Krylov kecil yaitu hanya 5. Ini cukup terbatas dalam konteks aplikasi realistis, tapi sudah cukup untuk contoh ini. Kita akan mengeksplorasi metode-metode dalam pelajaran selanjutnya yang memungkinkan kita untuk menskalakan dan memproyeksikan Hamiltonian kita ke subruang yang lebih besar.
# Set parameters for quantum Krylov algorithm
krylov_dim = 4 # size of krylov subspace
num_trotter_steps = 4
dt_circ = dt / num_trotter_steps
Persiapan keadaan
Pilih keadaan referensi yang memiliki tumpang tindih dengan keadaan dasar. Untuk Hamiltonian ini, kita menggunakan keadaan dengan eksitasi di qubit tengah sebagai keadaan referensi kita.
qc_state_prep = QuantumCircuit(n_qubits)
qc_state_prep.x(int(n_qubits / 2) + 1)
qc_state_prep.draw("mpl", scale=0.5)

Evolusi waktu
Kita bisa merealisasikan operator evolusi waktu yang dihasilkan oleh sebuah Hamiltonian tertentu: melalui aproksimasi Lie-Trotter. Demi kesederhanaan kita menggunakan PauliEvolutionGate bawaan dalam Circuit evolusi waktu. Sintaks umumnya adalah seperti ini.
t = Parameter("t")
## Create the time-evo op circuit
evol_gate = PauliEvolutionGate(
H_op, time=t, synthesis=LieTrotter(reps=num_trotter_steps)
)
qr = QuantumRegister(n_qubits)
qc_evol = QuantumCircuit(qr)
qc_evol.append(evol_gate, qargs=qr)
<qiskit.circuit.instructionset.InstructionSet at 0x7ccaa4664250>
Kita akan menggunakan versi ini di bawah dalam uji Hadamard, tapi dengan melangkah maju untuk waktu-waktu .
Uji Hadamard
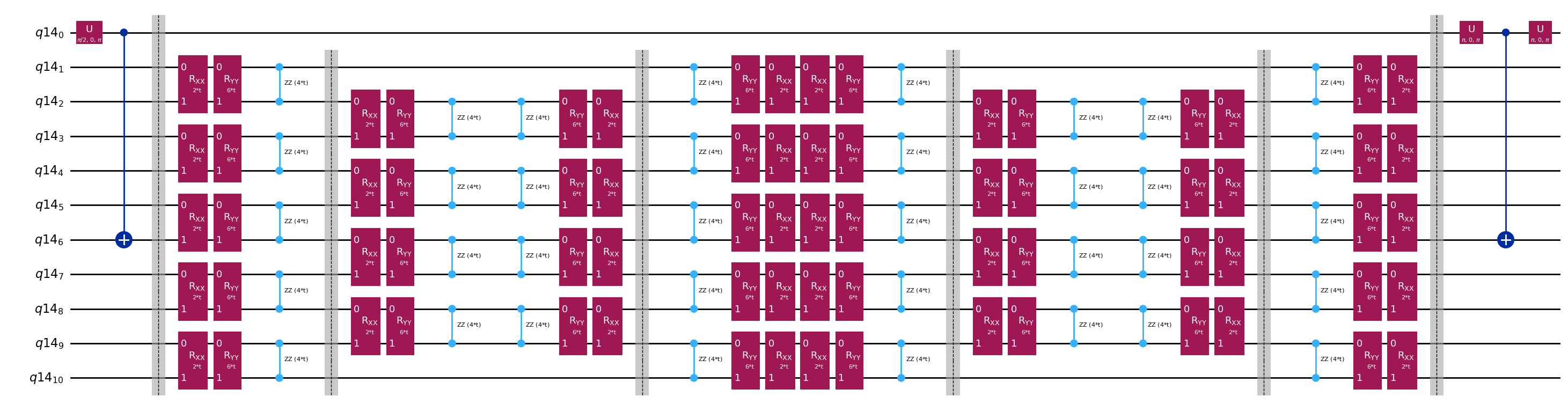
Ingat bahwa kita ingin menghitung elemen-elemen matriks dari dan matriks Gram menggunakan uji Hadamard. Mari kita tinjau cara kerjanya dalam konteks ini, dengan fokus pertama pada konstruksi Proses keseluruhan digambarkan secara grafis di bawah ini. Lapisan-lapisan blok persiapan keadaan berwarna berfungsi sebagai pengingat bahwa proses ini dilakukan untuk semua kombinasi dan dalam subruang kita.
Keadaan sistem pada langkah-langkah yang ditunjukkan adalah:
Di sini adalah suku Pauli dalam dekomposisi Hamiltonian (perhatikan bahwa ini tidak bisa berupa kombinasi linear dari beberapa suku Pauli yang komuting karena itu tidak akan uniter -- pengelompokan dimungkinkan menggunakan konstruksi berbeda yang akan kita tunjukkan nanti) , adalah operasi terkontrol yang mempersiapkan vektor , dari ruang Krylov uniter, dengan . Menerapkan pengukuran dan ke Circuit ini menghitung bagian nyata dan imajiner, masing-masing, dari elemen-elemen matriks yang kita butuhkan.
Mulai dari Langkah 4 di atas, terapkan Gate Hadamard ke qubit nol.
Kemudian ukur baik atau .
Dari identitas . Demikian pula, mengukur menghasilkan
Menambahkan langkah-langkah ini ke evolusi waktu yang sudah kita siapkan sebelumnya, kita menulis yang berikut.
## Create the time-evo op circuit
evol_gate = PauliEvolutionGate(
H_op, time=dt, synthesis=LieTrotter(reps=num_trotter_steps)
)
## Create the time-evo op dagger circuit
evol_gate_d = PauliEvolutionGate(
H_op, time=dt, synthesis=LieTrotter(reps=num_trotter_steps)
)
evol_gate_d = evol_gate_d.inverse()
# Put pieces together
qc_reg = QuantumRegister(n_qubits)
qc_temp = QuantumCircuit(qc_reg)
qc_temp.compose(qc_state_prep, inplace=True)
for _ in range(num_trotter_steps):
qc_temp.append(evol_gate, qargs=qc_reg)
for _ in range(num_trotter_steps):
qc_temp.append(evol_gate_d, qargs=qc_reg)
qc_temp.compose(qc_state_prep.inverse(), inplace=True)
# Create controlled version of the circuit
controlled_U = qc_temp.to_gate().control(1)
# Create hadamard test circuit for real part
qr = QuantumRegister(n_qubits + 1)
qc_real = QuantumCircuit(qr)
qc_real.h(0)
qc_real.append(controlled_U, list(range(n_qubits + 1)))
qc_real.h(0)
print("Circuit for calculating the real part of the overlap in S via Hadamard test")
qc_real.draw("mpl", fold=-1, scale=0.5)
Circuit for calculating the real part of the overlap in S via Hadamard test

Kita sudah memperingatkan sebelumnya tentang kedalaman yang terlibat dalam Circuit Trotter. Melakukan uji Hadamard dalam kondisi ini bisa menghasilkan Circuit yang bahkan lebih dalam, terutama setelah kita menguraikannya ke Gate-gate native. Ini akan meningkat lebih jauh lagi jika kita memperhitungkan topologi perangkat. Jadi sebelum menggunakan waktu apapun di komputer kuantum, ada baiknya memeriksa kedalaman 2-qubit dari Circuit kita.
print(
"Number of layers of 2Q operations",
qc_real.decompose(reps=2).depth(lambda x: x[0].num_qubits == 2),
)
Number of layers of 2Q operations 14401
Circuit dengan kedalaman ini tidak dapat menghasilkan hasil yang bisa digunakan pada komputer kuantum modern. Jika kita ingin membangun dan kita membutuhkan cara yang lebih baik. Inilah alasan untuk uji Hadamard yang efisien yang diperkenalkan di bawah.
4. 2 Langkah 2. Optimalkan Circuit dan operator untuk hardware target
Uji Hadamard yang efisien
Kita bisa mengoptimalkan Circuit yang dalam untuk uji Hadamard yang sudah kita peroleh dengan memperkenalkan beberapa aproksimasi dan mengandalkan beberapa asumsi tentang Hamiltonian model. Misalnya, perhatikan Circuit berikut untuk uji Hadamard:
Asumsikan kita bisa menghitung secara klasik , nilai eigen dari di bawah Hamiltonian . Ini terpenuhi ketika Hamiltonian mempertahankan simetri U(1). Meskipun ini mungkin terlihat seperti asumsi yang kuat, ada banyak kasus di mana aman untuk mengasumsikan bahwa ada keadaan vakum (dalam hal ini dipetakan ke keadaan ) yang tidak terpengaruh oleh aksi Hamiltonian. Ini benar misalnya untuk Hamiltonian kimia yang mendeskripsikan molekul stabil (di mana jumlah elektron dipertahankan). Mengingat bahwa Gate , mempersiapkan keadaan referensi yang diinginkan , misalnya, untuk mempersiapkan keadaan HF untuk kimia akan berupa produk dari NOT satu-qubit, sehingga terkontrol hanyalah produk dari CNOT. Kemudian Circuit di atas mengimplementasikan keadaan berikut sebelum pengukuran:
di mana kita menggunakan pergeseran fase yang bisa disimulasikan secara klasik dari langkah 2 ke 3. Karena itu nilai ekspektasinya adalah
Dengan menggunakan asumsi-asumsi ini kita dapat menulis nilai ekspektasi dari operator-operator yang diminati dengan operasi terkontrol yang lebih sedikit. Bahkan, kita hanya perlu mengimplementasikan persiapan keadaan terkontrol dan bukan evolusi waktu terkontrol. Memformulasi ulang perhitungan kita seperti di atas akan memungkinkan kita untuk sangat mengurangi kedalaman Circuit yang dihasilkan.
Perhatikan bahwa sebagai bonus, karena operator Pauli sekarang muncul sebagai pengukuran di akhir Circuit daripada sebagai Gate terkontrol di tengah, itu bisa diukur bersama dengan operator Pauli yang komuting lainnya seperti dalam dekomposisi yang diberikan di atas.
Uraikan operator evolusi waktu dengan dekomposisi Trotter
Alih-alih mengimplementasikan operator evolusi waktu secara tepat kita bisa menggunakan dekomposisi Trotter untuk mengimplementasikan aproksimasi dari operator tersebut. Mengulang beberapa kali dekomposisi Trotter orde tertentu memberikan pengurangan lebih lanjut dari kesalahan yang diperkenalkan dari aproksimasi. Berikut ini, kita langsung membangun implementasi Trotter dengan cara yang paling efisien untuk graf interaksi dari Hamiltonian yang kita pertimbangkan (hanya interaksi tetangga terdekat). Dalam praktiknya kita menyisipkan rotasi Pauli , , dengan sudut berparameter yang berhubungan dengan implementasi perkiraan dari . Mengingat perbedaan dalam definisi rotasi Pauli dan evolusi waktu yang ingin kita implementasikan, kita harus menggunakan parameter untuk mencapai evolusi waktu sebesar . Lebih lanjut, kita membalik urutan operasi untuk jumlah pengulangan langkah Trotter yang ganjil, yang secara fungsional setara tetapi memungkinkan penggabungan operasi yang berdekatan dalam satu uniter . Ini memberikan Circuit yang jauh lebih dangkal dibandingkan yang diperoleh menggunakan fungsionalitas generik PauliEvolutionGate().
t = Parameter("t")
# Create instruction for rotation about XX+YY-ZZ:
Rxyz_circ = QuantumCircuit(2)
Rxyz_circ.rxx(2 * JX * t, 0, 1)
Rxyz_circ.ryy(2 * JY * t, 0, 1)
Rxyz_circ.rzz(2 * JZ * t, 0, 1)
Rxyz_instr = Rxyz_circ.to_instruction(label="R J_x XX + J_y YY + J_z ZZ")
interaction_list = [
[[i, i + 1] for i in range(0, n_qubits - 1, 2)],
[[i, i + 1] for i in range(1, n_qubits - 1, 2)],
] # linear chain
qr = QuantumRegister(n_qubits)
trotter_step_circ = QuantumCircuit(qr)
for i, color in enumerate(interaction_list):
for interaction in color:
trotter_step_circ.append(Rxyz_instr, interaction)
if i < len(interaction_list) - 1:
trotter_step_circ.barrier()
reverse_trotter_step_circ = trotter_step_circ.reverse_ops()
qc_evol = QuantumCircuit(qr)
for step in range(num_trotter_steps):
if step % 2 == 0:
qc_evol = qc_evol.compose(trotter_step_circ)
else:
qc_evol = qc_evol.compose(reverse_trotter_step_circ)
qc_evol.decompose().draw("mpl", fold=-1, scale=0.5)
Kita mempersiapkan keadaan awal lagi untuk uji Hadamard yang efisien ini.
control = 0
excitation = int(n_qubits / 2) + 1
controlled_state_prep = QuantumCircuit(n_qubits + 1)
controlled_state_prep.cx(control, excitation)
controlled_state_prep.draw("mpl", fold=-1, scale=0.5)

Template Circuit untuk menghitung elemen matriks dari dan melalui uji Hadamard
Satu-satunya perbedaan antara Circuit yang digunakan dalam uji Hadamard adalah fase dalam operator evolusi waktu dan observable yang diukur. Karena itu kita bisa mempersiapkan Circuit template yang mewakili Circuit generik untuk uji Hadamard, dengan placeholder untuk gate-gate yang bergantung pada operator evolusi waktu.
# Parameters for the template circuits
parameters = []
for idx in range(1, krylov_dim):
parameters.append(dt_circ * (idx))
# Create modified hadamard test circuit
qr = QuantumRegister(n_qubits + 1)
qc = QuantumCircuit(qr)
qc.h(0)
qc.compose(controlled_state_prep, list(range(n_qubits + 1)), inplace=True)
qc.barrier()
qc.compose(qc_evol, list(range(1, n_qubits + 1)), inplace=True)
qc.barrier()
qc.x(0)
qc.compose(controlled_state_prep.inverse(), list(range(n_qubits + 1)), inplace=True)
qc.x(0)
qc.decompose().draw("mpl", fold=-1)
print(
"The optimized circuit has 2Q gates depth: ",
qc.decompose().decompose().depth(lambda x: x[0].num_qubits == 2),
)
The optimized circuit has 2Q gates depth: 50
Kedalaman ini berkurang secara substansial dibandingkan uji Hadamard asli. Kedalaman ini bisa ditangani oleh komputer kuantum modern, meskipun masih cukup tinggi. Kita perlu menggunakan mitigasi kesalahan mutakhir untuk mendapatkan hasil yang berguna.
Pilih Backend untuk menjalankan perhitungan Krylov kuantum kita, sehingga kita bisa mentranspilasi Circuit kita untuk dijalankan di komputer kuantum tersebut.
# Use the least-busy backend or specify a quantum computer using the syntax commented out below.
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
# Or you may choose a specify backend and channel if necessary for your workflow.
# service = QiskitRuntimeService(channel="ibm_quantum_platform")
# backend = service.backend("ibm_fez")
Kita sekarang mentranspilasi Circuit dan operator kita.
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
target = backend.target
basis_gates = list(target.operation_names)
pm = generate_preset_pass_manager(
optimization_level=3, backend=backend, basis_gates=basis_gates
)
qc_trans = pm.run(qc)
print(qc_trans.depth(lambda x: x[0].num_qubits == 2))
print(qc_trans.count_ops())
qc_trans.draw("mpl", fold=-1, idle_wires=False, scale=0.5)
36
OrderedDict([('rz', 410), ('sx', 361), ('cz', 156), ('x', 18), ('barrier', 6)])

Setelah optimasi, kedalaman dua-qubit Circuit yang ditranspilasi kita berkurang lebih jauh.
4.3 Langkah 3. Eksekusi menggunakan primitif Qiskit Runtime
Kita sekarang membuat PUB untuk eksekusi dengan Estimator.
# Define observables to measure for S
observable_S_real = "I" * (n_qubits) + "X"
observable_S_imag = "I" * (n_qubits) + "Y"
observable_op_real = SparsePauliOp(
observable_S_real
) # define a sparse pauli operator for the observable
observable_op_imag = SparsePauliOp(observable_S_imag)
layout = qc_trans.layout # get layout of transpiled circuit
observable_op_real = observable_op_real.apply_layout(
layout
) # apply physical layout to the observable
observable_op_imag = observable_op_imag.apply_layout(layout)
observable_S_real = (
observable_op_real.paulis.to_labels()
) # get the label of the physical observable
observable_S_imag = observable_op_imag.paulis.to_labels()
observables_S = [[observable_S_real], [observable_S_imag]]
# Define observables to measure for H
# Hamiltonian terms to measure
observable_list = []
for pauli, coeff in zip(H_op.paulis, H_op.coeffs):
# print(pauli)
observable_H_real = pauli[::-1].to_label() + "X"
observable_H_imag = pauli[::-1].to_label() + "Y"
observable_list.append([observable_H_real])
observable_list.append([observable_H_imag])
layout = qc_trans.layout
observable_trans_list = []
for observable in observable_list:
observable_op = SparsePauliOp(observable)
observable_op = observable_op.apply_layout(layout)
observable_trans_list.append([observable_op.paulis.to_labels()])
observables_H = observable_trans_list
# Define a sweep over parameter values
params = np.vstack(parameters).T
# Estimate the expectation value for all combinations of
# observables and parameter values, where the pub result will have
# shape (# observables, # parameter values).
pub = (qc_trans, observables_S + observables_H, params)
Circuit untuk bisa dihitung secara klasik. Kita lakukan ini sebelum beralih ke kasus menggunakan komputer kuantum.
from qiskit.quantum_info import StabilizerState, Pauli
qc_cliff = qc.assign_parameters({t: 0})
# Get expectation values from experiment
S_expval_real = StabilizerState(qc_cliff).expectation_value(
Pauli("I" * (n_qubits) + "X")
)
S_expval_imag = StabilizerState(qc_cliff).expectation_value(
Pauli("I" * (n_qubits) + "Y")
)
# Get expectation values
S_expval = S_expval_real + 1j * S_expval_imag
H_expval = 0
for obs_idx, (pauli, coeff) in enumerate(zip(H_op.paulis, H_op.coeffs)):
# Get expectation values from experiment
expval_real = StabilizerState(qc_cliff).expectation_value(
Pauli(pauli[::-1].to_label() + "X")
)
expval_imag = StabilizerState(qc_cliff).expectation_value(
Pauli(pauli[::-1].to_label() + "Y")
)
expval = expval_real + 1j * expval_imag
# Fill-in matrix elements
H_expval += coeff * expval
print(H_expval)
(10+0j)
Meskipun kita berhasil mengurangi kedalaman gate kita dengan beberapa orde besaran menggunakan uji Hadamard yang efisien, kedalamannya masih cukup untuk memerlukan mitigasi kesalahan mutakhir. Di bawah ini, kita menentukan atribut dari mitigasi yang digunakan. Semua metode yang digunakan penting, tapi ada baiknya menyebutkan secara khusus probabilistic error amplification (PEA). Teknik yang kuat ini datang dengan overhead kuantum yang besar. Perhitungan yang dilakukan di sini bisa memakan waktu 20 menit atau lebih untuk dijalankan di komputer kuantum nyata. Kamu mungkin ingin bermain-main dengan parameter di bawah ini untuk meningkatkan atau menurunkan presisi dan konsekuensinya overhead. Pengaturan default di bawah ini menghasilkan hasil dengan fidelitas tinggi.
# Experiment options
num_randomizations = 300
num_randomizations_learning = 20
max_batch_circuits = 20
shots_per_randomization = 100
learning_pair_depths = [0, 4, 24]
noise_factors = [1, 1.3, 1.6]
# Base option formatting
options = {
# Builtin resilience settings for ZNE
"resilience": {
"measure_mitigation": True,
"zne_mitigation": True,
"zne": {"noise_factors": noise_factors},
# TREX noise learning configuration
"measure_noise_learning": {
"num_randomizations": num_randomizations_learning,
"shots_per_randomization": shots_per_randomization,
},
# PEA noise model configuration
"layer_noise_learning": {
"max_layers_to_learn": 10,
"layer_pair_depths": learning_pair_depths,
"shots_per_randomization": shots_per_randomization,
"num_randomizations": num_randomizations_learning,
},
},
# Randomization configuration
"twirling": {
"num_randomizations": num_randomizations,
"shots_per_randomization": shots_per_randomization,
"strategy": "all",
},
# Experimental settings for PEA method
"experimental": {
# # Just in case, disable any further qiskit transpilation not related to twirling / DD
# "skip_transpilation": True,
# Execution configuration
"execution": {
"max_pubs_per_batch_job": max_batch_circuits,
"fast_parametric_update": True,
},
# Error Mitigation configuration
"resilience": {
# ZNE Configuration
"zne": {
"amplifier": "pea",
"return_all_extrapolated": True,
"return_unextrapolated": True,
"extrapolated_noise_factors": [0] + noise_factors,
}
},
},
}
Akhirnya, kita mengeksekusi Circuit untuk dan dengan Estimator.
# This job required 17 minutes of QPU time to run on a Heron r2 processor. This is only an estimate.
# Your execution time may vary.
with Batch(backend=backend) as batch:
# Estimator
estimator = Estimator(mode=batch, options=options)
job = estimator.run([pub], precision=1)
4.4 Langkah 4. Pasca-proses dan analisis hasil
Apa yang kita peroleh dari komputer kuantum adalah elemen-elemen matriks individual dari dan kelompok-kelompok Pauli yang komuting yang membentuk elemen-elemen matriks dari . Suku-suku ini harus digabungkan untuk memulihkan matriks kita, sehingga kita bisa memecahkan masalah nilai eigen terampat.
# Store the outputs as 'results'.
results = job.result()[0]
Hitung Hamiltonian Efektif dan matriks Tumpang Tindih
Pertama hitung fase yang terakumulasi oleh keadaan selama evolusi waktu yang tidak terkontrol
prefactors = [
np.exp(-1j * sum([c for p, c in H_op.to_list() if "Z" in p]) * i * dt)
for i in range(1, krylov_dim)
]
Setelah kita mendapatkan hasil eksekusi Circuit, kita bisa memproses data untuk menghitung elemen-elemen matriks dari
# Assemble S, the overlap matrix of dimension D:
S_first_row = np.zeros(krylov_dim, dtype=complex)
S_first_row[0] = 1 + 0j
# Add in ancilla-only measurements:
for i in range(krylov_dim - 1):
# Get expectation values from experiment
expval_real = results.data.evs[0][0][i] # automatic extrapolated evs if ZNE is used
expval_imag = results.data.evs[1][0][i] # automatic extrapolated evs if ZNE is used
# Get expectation values
expval = expval_real + 1j * expval_imag
S_first_row[i + 1] += prefactors[i] * expval
S_first_row_list = S_first_row.tolist() # for saving purposes
S_circ = np.zeros((krylov_dim, krylov_dim), dtype=complex)
# Distribute entries from first row across matrix:
for i, j in it.product(range(krylov_dim), repeat=2):
if i >= j:
S_circ[j, i] = S_first_row[i - j]
else:
S_circ[j, i] = np.conj(S_first_row[j - i])
from sympy import Matrix
Matrix(S_circ)
Dan elemen-elemen matriks dari
import itertools
# Assemble S, the overlap matrix of dimension D:
H_first_row = np.zeros(krylov_dim, dtype=complex)
H_first_row[0] = H_expval
for obs_idx, (pauli, coeff) in enumerate(zip(H_op.paulis, H_op.coeffs)):
# Add in ancilla-only measurements:
for i in range(krylov_dim - 1):
# Get expectation values from experiment
expval_real = results.data.evs[2 + 2 * obs_idx][0][
i
] # automatic extrapolated evs if ZNE is used
expval_imag = results.data.evs[2 + 2 * obs_idx + 1][0][
i
] # automatic extrapolated evs if ZNE is used
# Get expectation values
expval = expval_real + 1j * expval_imag
H_first_row[i + 1] += prefactors[i] * coeff * expval
H_first_row_list = H_first_row.tolist()
H_eff_circ = np.zeros((krylov_dim, krylov_dim), dtype=complex)
# Distribute entries from first row across matrix:
for i, j in itertools.product(range(krylov_dim), repeat=2):
if i >= j:
H_eff_circ[j, i] = H_first_row[i - j]
else:
H_eff_circ[j, i] = np.conj(H_first_row[j - i])
from sympy import Matrix
Matrix(H_eff_circ)
Akhirnya, kita bisa memecahkan masalah nilai eigen terampat untuk :
dan mendapatkan estimasi energi keadaan dasar
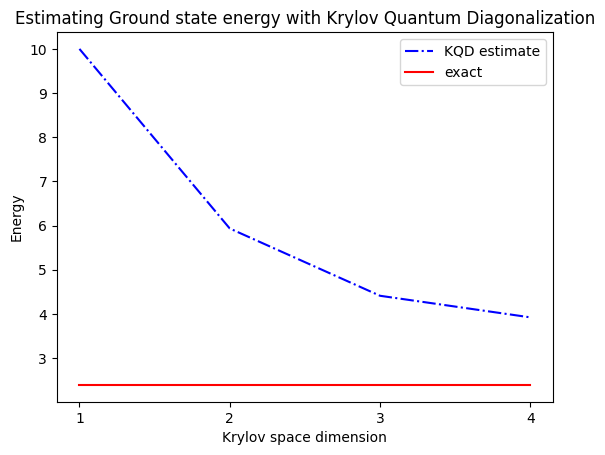
gnd_en_circ_est_list = []
for d in range(1, krylov_dim + 1):
# Solve generalized eigenvalue problem
gnd_en_circ_est = solve_regularized_gen_eig(
H_eff_circ[:d, :d], S_circ[:d, :d], threshold=1e-1
)
gnd_en_circ_est_list.append(gnd_en_circ_est)
print("The estimated ground state energy is: ", gnd_en_circ_est)
The estimated ground state energy is: 10.0
The estimated ground state energy is: 5.933953916292923
The estimated ground state energy is: 4.4101773995740645
The estimated ground state energy is: 3.921288588521255
Untuk sektor partikel tunggal, kita bisa menghitung secara efisien keadaan dasar dari sektor Hamiltonian ini secara klasik
gs_en = single_particle_gs(H_op, n_qubits)
n_sys_qubits 10
n_exc 1 , subspace dimension 11
single particle ground state energy: 2.391547869638771
len(H_op)
27
plt.plot(
range(1, krylov_dim + 1),
gnd_en_circ_est_list,
color="blue",
linestyle="-.",
label="KQD estimate",
)
plt.plot(
range(1, krylov_dim + 1),
[gs_en] * krylov_dim,
color="red",
linestyle="-",
label="exact",
)
plt.xticks(range(1, krylov_dim + 1), range(1, krylov_dim + 1))
plt.legend()
plt.xlabel("Krylov space dimension")
plt.ylabel("Energy")
plt.title("Estimating Ground state energy with Krylov Quantum Diagonalization")
plt.show()
5. Diskusi dan Pengembangan
Sebagai ringkasan, kita mulai dengan state referensi, lalu mengevolusinya selama berbagai periode waktu untuk menghasilkan subspace Krylov uniter. Kita memproyeksikan Hamiltonian kita ke subspace tersebut. Kita juga memperkirakan overlap dari vektor-vektor subspace. Terakhir, kita menyelesaikan masalah nilai eigen tergeneralisasi berdimensi lebih rendah secara klasikal.
Mari kita bandingkan apa yang menentukan biaya komputasi dari penggunaan teknik Krylov secara klasikal dan kuantum. Tidak ada analogi sempurna antara pendekatan klasikal dan kuantum untuk semua langkah. Tabel ini mengumpulkan beberapa penskalaan dari langkah-langkah berbeda untuk pertimbangan.
Ingat bahwa Hamiltonian umumnya memiliki suku-suku yang tidak bisa diukur secara bersamaan (karena tidak berkomutasi satu sama lain). Kita mengelompokkan suku-suku dalam Hamiltonian ke dalam grup operator Pauli yang berkomutasi dan bisa diukur secara bersamaan, dan kita mungkin membutuhkan banyak grup seperti itu untuk memperhitungkan semua suku yang tidak berkomutasi satu sama lain. Untuk membangun di komputer kuantum memerlukan pengukuran terpisah untuk setiap grup string Pauli yang berkomutasi dalam Hamiltonian, dan masing-masing membutuhkan banyak shots. Kita harus melakukan ini untuk elemen matriks yang berbeda, yang bersesuaian dengan kombinasi faktor evolusi waktu yang berbeda. Kadang ada cara untuk mengurangi ini, namun dalam perlakuan kasar ini, waktu yang dibutuhkan untuk ini berskala seperti Elemen-elemen harus diestimasi, yang berskala seperti . Terakhir, menyelesaikan masalah nilai eigen tergeneralisasi di ruang yang diproyeksikan, secara klasikal, membutuhkan
Kita melihat bahwa diagonalisasi Krylov kuantum mungkin berguna dalam kasus-kasus di mana jumlah grup Pauli yang berkomutasi dalam Hamiltonian relatif kecil. Ketergantungan penskalaan ini menunjukkan beberapa aplikasi di mana metode Krylov dapat berguna, dan yang lain kemungkinan tidak. Beberapa Hamiltonian memiliki kompleksitas tinggi ketika dipetakan ke qubit, melibatkan banyak string Pauli yang tidak berkomutasi dan tidak mudah dipartisi menjadi beberapa grup yang berkomutasi. Ini sering berlaku untuk masalah kimia kuantum, misalnya. Kompleksitas ini menghadirkan dua tantangan utama untuk komputer kuantum jangka dekat:
- Estimasi setiap elemen menjadi mahal secara komputasi karena banyaknya suku.
- Circuit Trotter yang dibutuhkan menjadi terlalu dalam.
Kedua poin di atas akan menjadi kurang bermasalah ketika komputer kuantum mencapai toleransi kesalahan, namun harus dipertimbangkan dalam jangka dekat. Bahkan sistem dengan pemetaan yang "lebih sederhana" dari pada kimia kuantum mungkin mengalami hambatan yang sama, jika Hamiltoniannya memiliki terlalu banyak suku yang tidak berkomutasi. Metode Krylov paling berguna ketika Hamiltonian dapat dipartisi menjadi relatif sedikit grup Pauli yang berkomutasi, dan di mana mudah diimplementasikan dalam circuit Trotter. Kedua kondisi ini terpenuhi, misalnya, untuk banyak model kisi yang menarik dalam fisika. KQD sangat berguna jika sangat sedikit yang diketahui tentang ground state. Ini berasal dari jaminan konvergensi yang melekat padanya dan penerapannya dalam skenario di mana metode alternatif tidak dapat digunakan karena pengetahuan ground state yang tidak memadai.
Meskipun KQD adalah alat yang kuat, aspek-aspek protokol yang memakan waktu, terutama estimasi setiap elemen Hamiltonian yang diproyeksikan dan overlap state Krylov, merupakan peluang untuk perbaikan. Pendekatan alternatif melibatkan pemanfaatan metode Krylov bersama dengan metode berbasis sampling, yang menjadi subjek pelajaran berikutnya.
6. Lampiran
Lampiran I: Subspace Krylov dari evolusi waktu riil
Ruang Krylov uniter didefinisikan sebagai
untuk beberapa langkah waktu yang akan kita tentukan nanti. Sementara itu anggap genap: maka definisikan . Perhatikan bahwa ketika kita memproyeksikan Hamiltonian ke ruang Krylov di atas, itu tidak dapat dibedakan dari ruang Krylov
yaitu, di mana semua evolusi waktu digeser mundur sebesar langkah waktu. Alasannya tidak dapat dibedakan adalah karena elemen matriks
tidak berubah di bawah pergeseran keseluruhan waktu evolusi, karena evolusi waktu berkomutasi dengan Hamiltonian. Untuk ganjil, kita bisa menggunakan analisis untuk .
Kita ingin menunjukkan bahwa di suatu tempat dalam ruang Krylov ini, dijamin ada state berenergi rendah. Kita lakukan ini melalui hasil berikut, yang diturunkan dari Teorema 3.1 dalam [3]:
Klaim 1: ada fungsi sedemikian sehingga untuk energi dalam rentang spektral Hamiltonian (yaitu, antara energi ground state dan energi maksimum)...
- untuk semua nilai yang berada dari , artinya teredam secara eksponensial
- adalah kombinasi linear dari untuk
Kita berikan pembuktian di bawah, namun bisa dilewati dengan aman kecuali ingin memahami argumen yang lengkap dan ketat. Untuk saat ini kita fokus pada implikasi dari klaim di atas. Berdasarkan properti 3 di atas, kita bisa melihat bahwa ruang Krylov yang digeser di atas mengandung state . Inilah state berenergi rendah kita. Untuk memahami alasannya, tulis dalam basis eigen energi:
di mana adalah eigenstate energi ke-k dan adalah amplitudonya dalam state awal . Dinyatakan dalam hal ini, diberikan oleh
menggunakan fakta bahwa kita bisa mengganti dengan saat ia bekerja pada eigenstate . Kesalahan energi dari state ini karena itu adalah
Untuk mengubah ini menjadi batas atas yang lebih mudah dipahami, pertama kita pisahkan jumlah di pembilang menjadi suku-suku dengan dan suku-suku dengan :
Kita bisa membatasi dari atas suku pertama dengan ,
di mana langkah pertama mengikuti karena untuk setiap dalam jumlah tersebut, dan langkah kedua mengikuti karena jumlah di pembilang adalah subset dari jumlah di penyebut. Untuk suku kedua, pertama kita batasi dari bawah penyebutnya dengan , karena : menjumlahkan semuanya kembali, ini memberikan
Untuk menyederhanakan yang tersisa, perhatikan bahwa untuk semua ini, berdasarkan definisi kita tahu bahwa . Selain itu membatasi dari atas dan membatasi dari atas memberikan
Ini berlaku untuk sembarang , jadi jika kita menetapkan sama dengan kesalahan target kita, maka batas kesalahan di atas konvergen ke target tersebut secara eksponensial dengan dimensi Krylov . Perhatikan juga bahwa jika maka suku sebenarnya hilang sepenuhnya dalam batas di atas.
Untuk melengkapi argumen, pertama kita catat bahwa di atas hanyalah kesalahan energi dari state tertentu , bukan kesalahan energi dari state berenergi terendah dalam ruang Krylov. Namun, berdasarkan prinsip variasional (Rayleigh-Ritz), kesalahan energi dari state berenergi terendah dalam ruang Krylov dibatasi dari atas oleh kesalahan energi dari sembarang state dalam ruang Krylov, sehingga di atas juga merupakan batas atas pada kesalahan energi dari state berenergi terendah, yaitu, keluaran dari algoritma diagonalisasi Krylov kuantum.
Analisis serupa seperti di atas dapat dilakukan yang juga memperhitungkan noise dan prosedur thresholding yang dibahas dalam notebook. Lihat [2] dan [4] untuk analisis ini.
Lampiran II: Pembuktian Klaim 1
Berikut ini sebagian besar diturunkan dari [3], Teorema 3.1: misalkan dan misalkan adalah ruang polinomial residual (polinomial yang nilainya di 0 adalah 1) berderajat paling banyak . Solusi dari
adalah
dan nilai minimal yang bersesuaian adalah
Kita ingin mengubah ini menjadi fungsi yang dapat dinyatakan secara alami dalam bentuk eksponensial kompleks, karena itulah evolusi waktu riil yang menghasilkan ruang Krylov kuantum. Untuk melakukannya, lebih mudah untuk memperkenalkan transformasi energi dalam rentang spektral Hamiltonian ke bilangan dalam rentang : definisikan
di mana adalah langkah waktu sedemikian sehingga . Perhatikan bahwa dan bertumbuh seiring bergerak menjauh dari .
Sekarang menggunakan polinomial dengan parameter a, b, d diatur ke , , dan d = int(r/2), kita mendefinisikan fungsi:
di mana adalah energi ground state. Kita bisa melihat dengan memasukkan bahwa adalah polinomial trigonometri berderajat , yaitu, kombinasi linear dari untuk . Selanjutnya, dari definisi di atas kita memiliki bahwa dan untuk sembarang dalam rentang spektral sedemikian sehingga kita memiliki
Referensi:
[1] https://arxiv.org/abs/2407.14431
[2] https://arxiv.org/abs/1811.09025
[3] https://people.math.ethz.ch/~mhg/pub/biksm.pdf
[4] https://academic.oup.com/book/36426
[5] https://en.wikipedia.org/wiki/Krylov_subspace
[6] Krylov Subspace Methods: Principles and Analysis, Jörg Liesen, Zdenek Strakos https://academic.oup.com/book/36426
[7] Iterative Methods for Sparse Linear Systems" by Yousef Saad
[8] "MINRES-QLP: A Krylov Subspace Method for Indefinite or Singular Symmetric Systems" by Sou-Cheng Choi, Christopher Paige, and Michael Saunders (https://epubs.siam.org/doi/10.1137/100787921)
[9] Ethan N. Epperly, Lin Lin, and Yuji Nakatsukasa. "A theory of quantum subspace diagonalization". SIAM Journal on Matrix Analysis and Applications 43, 1263–1290 (2022).