Encoding data
Pendahuluan dan notasi
Untuk menggunakan algoritma kuantum, data klasik harus dibawa ke dalam Circuit kuantum. Ini biasanya disebut encoding data, tapi juga bisa disebut loading data. Ingat dari pelajaran sebelumnya tentang konsep feature mapping, yaitu pemetaan fitur data dari satu ruang ke ruang lain. Sekadar memindahkan data klasik ke komputer kuantum sudah merupakan semacam pemetaan, dan bisa disebut feature mapping. Dalam praktiknya, feature mapping bawaan di Qiskit (seperti z_feature_map dan zz_feature_map) biasanya menyertakan lapisan rotasi dan lapisan entangling yang memperluas state ke banyak dimensi di Hilbert space. Proses encoding ini adalah bagian kritis dari algoritma quantum machine learning dan langsung memengaruhi kemampuan komputasinya.
Beberapa teknik encoding di bawah ini bisa disimulasikan secara klasik dengan efisien; ini khususnya mudah dilihat pada metode encoding yang menghasilkan product states (artinya, tidak mengentangle qubit). Dan ingat bahwa quantum utility paling mungkin ada di mana kompleksitas kuantum dari dataset cocok dengan metode encoding. Jadi sangat mungkin kamu akan membuat Circuit encoding sendiri. Di sini, kami menampilkan berbagai strategi encoding yang mungkin supaya kamu bisa membandingkan satu sama lain dan melihat apa yang bisa dilakukan. Ada beberapa pernyataan umum yang bisa dibuat tentang kegunaan teknik encoding. Misalnya, efficient_su2 (lihat di bawah) dengan skema entangling penuh jauh lebih mungkin menangkap fitur kuantum dari data dibanding metode yang menghasilkan product states (seperti z_feature_map). Tapi ini tidak berarti efficient_su2 sudah cukup, atau cukup cocok untuk datasetmu, untuk menghasilkan quantum speed-up. Itu membutuhkan pertimbangan cermat tentang struktur data yang dimodelkan atau diklasifikasikan. Ada juga trade-off dengan kedalaman Circuit, karena banyak feature map yang sepenuhnya mengentangle qubit dalam Circuit menghasilkan Circuit yang sangat dalam, terlalu dalam untuk mendapatkan hasil yang berguna di komputer kuantum saat ini.
Notasi
Dataset adalah himpunan vektor data: , di mana setiap vektor berdimensi , yaitu . Ini bisa diperluas ke fitur data kompleks. Dalam pelajaran ini, kami sesekali menggunakan notasi untuk himpunan penuh dan elemen spesifiknya seperti . Tapi kami sebagian besar akan mengacu pada loading satu vektor dari dataset kita dalam satu waktu, dan sering hanya menyebut satu vektor dengan fitur sebagai .
Selain itu, biasa menggunakan simbol untuk merujuk pada feature mapping dari vektor data . Dalam komputasi kuantum khususnya, umum untuk merujuk pada pemetaan menggunakan sebuah notasi yang memperkuat sifat uniter dari operasi ini. Keduanya bisa digunakan dengan benar; keduanya adalah feature mapping. Sepanjang kursus ini, kami cenderung menggunakan:
- saat membahas feature mapping dalam machine learning secara umum, dan
- saat membahas implementasi Circuit dari feature mapping.
Normalisasi dan kehilangan informasi
Dalam classical machine learning, fitur data training sering "dinormalisasi" atau diubah skalanya yang sering meningkatkan performa model. Salah satu cara umum melakukan ini adalah dengan menggunakan normalisasi min-max atau standardisasi. Dalam normalisasi min-max, kolom fitur dari matriks data (misalnya, fitur ) dinormalisasi:
di mana min dan max mengacu pada nilai minimum dan maksimum fitur atas vektor data dalam dataset . Semua nilai fitur kemudian berada dalam interval unit: untuk semua , .
Normalisasi juga merupakan konsep fundamental dalam mekanika kuantum dan komputasi kuantum, tapi sedikit berbeda dari normalisasi min-max. Normalisasi dalam mekanika kuantum mensyaratkan bahwa panjang (dalam konteks komputasi kuantum, 2-norm) dari vektor state sama dengan satu: , memastikan bahwa probabilitas pengukuran berjumlah 1. State dinormalisasi dengan membaginya dengan 2-norm; yaitu, dengan mengubah skala
Dalam komputasi kuantum dan mekanika kuantum, ini bukan normalisasi yang dipaksakan orang pada data, tapi properti fundamental dari state kuantum. Bergantung pada skema encoding-mu, batasan ini bisa memengaruhi cara data diubah skalanya. Misalnya, dalam amplitude encoding (lihat di bawah), vektor data dinormalisasi seperti yang disyaratkan oleh mekanika kuantum, dan ini memengaruhi skala data yang di-encode. Dalam phase encoding, nilai fitur disarankan untuk diubah skalanya sebagai agar tidak ada kehilangan informasi akibat efek modulo- dari encoding ke sudut fase qubit[1,2].
Metode encoding
Dalam beberapa bagian berikutnya, kami akan merujuk pada dataset klasik contoh kecil yang terdiri dari vektor data, masing-masing dengan fitur:
Dalam notasi yang diperkenalkan di atas, kita bisa mengatakan fitur ke- dari vektor data ke- dalam himpunan kita adalah misalnya.
Basis encoding
Basis encoding meng-encode string -bit klasik ke dalam computational basis state dari sistem -Qubit. Ambil contoh Ini bisa direpresentasikan sebagai string -bit sebagai , dan oleh sistem -Qubit sebagai state kuantum . Secara lebih umum, untuk string -bit: , state -Qubit yang sesuai adalah dengan untuk . Perhatikan bahwa ini hanya untuk satu fitur saja.
Basis encoding dalam komputasi kuantum merepresentasikan setiap bit klasik sebagai qubit terpisah, memetakan representasi biner data langsung ke state kuantum dalam basis komputasi. Ketika beberapa fitur perlu di-encode, setiap fitur pertama dikonversi ke bentuk binernya dan kemudian ditetapkan ke kelompok qubit yang berbeda — satu kelompok per fitur — di mana setiap qubit mencerminkan satu bit dalam representasi biner dari fitur tersebut.
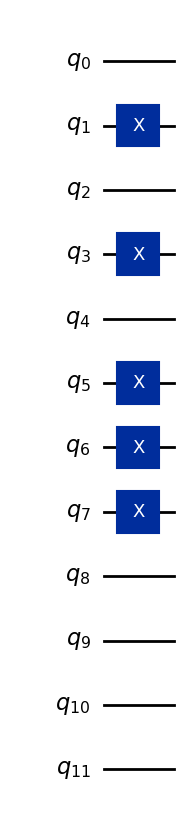
Sebagai contoh, mari kita encode vektor (5, 7, 0).
Misalkan semua fitur disimpan dalam empat bit (lebih dari yang kita butuhkan, tapi cukup untuk merepresentasikan bilangan bulat satu digit dalam basis 10):
5 → binary 0101
7 → binary 0111
0 → binary 0000
String bit ini ditetapkan ke tiga set empat qubit, sehingga basis state 12-Qubit keseluruhan adalah:
Di sini, empat qubit pertama merepresentasikan fitur pertama, empat qubit berikutnya fitur kedua, dan empat qubit terakhir fitur ketiga. Kode di bawah mengonversi vektor data (5,7,0) ke state kuantum, dan digeneralisasi untuk melakukan hal yang sama untuk fitur satu digit lainnya.
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit
from qiskit import QuantumCircuit
# Data point to encode
x = 5 # binary: 0101
y = 7 # binary: 0111
z = 0 # binary: 0000
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, "04b")] # [0,1,0,1]
y_bits = [int(b) for b in format(y, "04b")] # [0,1,1,1]
z_bits = [int(b) for b in format(z, "04b")] # [0,0,0,0]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,1,0,1,1,1,0,0,0,0]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw("mpl")
Cek pemahamanmu
Baca pertanyaan di bawah, pikirkan jawabanmu, lalu klik segitiga untuk melihat solusinya.
Tulis kode untuk meng-encode vektor pertama dalam dataset contoh kita :
menggunakan basis encoding.
Jawaban:
import math
from qiskit import QuantumCircuit
# Data point to encode
x = 4 # binary: 0100
y = 8 # binary: 1000
z = 5 # binary: 0101
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, '04b')] # [0,1,0,0]
y_bits = [int(b) for b in format(y, '04b')] # [1,0,0,0]
z_bits = [int(b) for b in format(z, '04b')] # [0,1,0,1]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,0,1,0,0,0,0,1,0,1]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw('mpl')
Amplitude encoding
Amplitude encoding meng-encode data ke dalam amplitudo dari state kuantum. Ini merepresentasikan vektor data klasik -dimensi yang ternormalisasi, , sebagai amplitudo dari state kuantum -Qubit, :
di mana adalah dimensi vektor data yang sama seperti sebelumnya, adalah elemen ke- dari dan adalah computational basis state ke-. Di sini, adalah konstanta normalisasi yang ditentukan dari data yang di-encode. Ini adalah kondisi normalisasi yang dipaksakan oleh mekanika kuantum:
Secara umum, ini adalah kondisi yang berbeda dari normalisasi min/max yang digunakan untuk setiap fitur di semua vektor data. Cara menavigasinya akan bergantung pada masalahmu. Tapi tidak ada cara untuk menghindari kondisi normalisasi mekanika kuantum di atas.
Dalam amplitude encoding, setiap fitur dalam vektor data disimpan sebagai amplitudo dari state kuantum yang berbeda. Karena sistem qubit menyediakan amplitudo, amplitude encoding dari fitur membutuhkan qubit.
Sebagai contoh, mari kita encode vektor pertama dalam dataset contoh , menggunakan amplitude encoding. Menormalisasi vektor yang dihasilkan, kita mendapatkan:
dan state kuantum 2-Qubit yang dihasilkan adalah:
Dalam contoh di atas, jumlah fitur dalam vektor , bukan pangkat dari 2. Ketika bukan pangkat dari 2, kita cukup memilih nilai untuk jumlah qubit sehingga dan menambahkan padding pada vektor amplitudo dengan konstanta yang tidak informatif (di sini, nol).
Seperti dalam basis encoding, setelah kita menghitung state apa yang akan meng-encode dataset kita, di Qiskit kita bisa menggunakan fungsi initialize untuk menyiapkannya:
import math
desired_state = [
1 / math.sqrt(105) * 4,
1 / math.sqrt(105) * 8,
1 / math.sqrt(105) * 5,
1 / math.sqrt(105) * 0,
]
qc = QuantumCircuit(2)
qc.initialize(desired_state, [0, 1])
qc.decompose(reps=5).draw(output="mpl")

Keuntungan dari amplitude encoding adalah persyaratan hanya qubit untuk encoding. Namun, algoritma berikutnya harus beroperasi pada amplitudo state kuantum, dan metode untuk menyiapkan dan mengukur state kuantum cenderung tidak efisien.
Cek pemahamanmu
Baca pertanyaan di bawah, pikirkan jawabanmu, lalu klik segitiga untuk melihat solusinya.
Tuliskan state yang ternormalisasi untuk meng-encode vektor berikut (terdiri dari dua vektor dari dataset contoh kita):
menggunakan amplitude encoding.
Jawaban:
Untuk meng-encode 6 angka, kita perlu memiliki setidaknya 6 state yang tersedia di mana amplitudonya bisa di-encode. Ini membutuhkan 3 qubit. Menggunakan faktor normalisasi yang tidak diketahui , kita bisa menulisnya sebagai:
Perhatikan bahwa
Jadi akhirnya,
Untuk vektor data yang sama tulis kode untuk membuat Circuit yang memuat fitur data ini menggunakan amplitude encoding.
Jawaban:
desired_state = [
9 / math.sqrt(270),
8 / math.sqrt(270),
6 / math.sqrt(270),
2 / math.sqrt(270),
9 / math.sqrt(270),
2 / math.sqrt(270),
0,
0,
]
print(desired_state)
qc = QuantumCircuit(3)
qc.initialize(desired_state, [0, 1, 2])
qc.decompose(reps=8).draw(output="mpl")
[0.5477225575051662, 0.48686449556014766, 0.36514837167011077, 0.12171612389003691, 0.5477225575051662, 0.12171612389003691, 0, 0]

Kamu mungkin perlu menangani vektor data yang sangat besar. Pertimbangkan vektor
Tulis kode untuk mengotomatiskan normalisasi, dan hasilkan Circuit kuantum untuk amplitude encoding.
Jawaban:
Ada banyak kemungkinan jawaban. Berikut adalah kode yang mencetak beberapa langkah di sepanjang jalan:
import numpy as np
from math import sqrt
init_list = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5]
qubits = round(np.log(len(init_list)) / np.log(2) + 0.4999999999)
need_length = 2**qubits
pad = need_length - len(init_list)
for i in range(0, pad):
init_list.append(0)
init_array = np.array(init_list) # Unnormalized data vector
length = sqrt(
sum(init_array[i] ** 2 for i in range(0, len(init_array)))
) # Vector length
norm_array = init_array / length # Normalized array
print("Normalized array:")
print(norm_array)
print()
qubit_numbers = []
for i in range(0, qubits):
qubit_numbers.append(i)
print(qubit_numbers)
qc = QuantumCircuit(qubits)
qc.initialize(norm_array, qubit_numbers)
qc.decompose(reps=7).draw(output="mpl")
Normalized array: [0.17342199 0.34684399 0.21677749 0.39019949 0.34684399 0.26013299 0.086711 0.39019949 0.086711 0.21677749 0.30348849 0. 0.1300665 0.30348849 0.21677749 0. ]
[0, 1, 2, 3]
Apakah kamu melihat keuntungan amplitude encoding dibanding basis encoding? Kalau iya, jelaskan.
Jawaban:
Mungkin ada beberapa jawaban. Salah satu jawabannya adalah bahwa, mengingat urutan basis state yang tetap, amplitude encoding ini mempertahankan urutan angka yang di-encode. Ini juga sering di-encode lebih padat.
Keuntungan dari amplitude encoding adalah bahwa hanya qubit yang diperlukan untuk vektor data -dimensi (-fitur) . Namun, amplitude encoding pada umumnya adalah prosedur yang tidak efisien yang memerlukan persiapan state sembarang, yang bersifat eksponensial dalam jumlah Gate CNOT. Dengan kata lain, persiapan state memiliki kompleksitas runtime polinomial dalam jumlah dimensi, di mana , dan adalah jumlah qubit. Amplitude encoding "memberikan penghematan eksponensial dalam ruang dengan biaya peningkatan eksponensial dalam waktu"[3]; namun, peningkatan runtime menjadi dapat dicapai dalam kasus tertentu[4]. Untuk quantum speedup end-to-end, kompleksitas runtime loading data perlu dipertimbangkan.
Angle encoding
Angle encoding menarik perhatian dalam banyak model QML yang menggunakan Pauli feature map seperti quantum support vector machine (QSVM) dan variational quantum circuit (VQC), di antara yang lain. Angle encoding erat kaitannya dengan phase encoding dan dense angle encoding yang disajikan di bawah. Di sini kami akan menggunakan "angle encoding" untuk merujuk pada rotasi dalam , yaitu rotasi menjauhi sumbu yang dilakukan misalnya oleh Gate atau Gate [1,3]. Sebenarnya, data bisa di-encode dalam rotasi manapun atau kombinasi rotasi. Tapi umum dalam literatur, jadi kami menekankannya di sini.
Ketika diterapkan pada satu qubit, angle encoding memberikan rotasi sumbu Y yang proporsional dengan nilai data. Pertimbangkan encoding satu fitur ke- dari vektor data ke- dalam dataset, :
Sebagai alternatif, angle encoding bisa dilakukan menggunakan Gate , meskipun state yang di-encode akan memiliki fase relatif kompleks dibandingkan dengan .
Angle encoding berbeda dari dua metode sebelumnya yang dibahas dalam beberapa hal. Dalam angle encoding:
- Setiap nilai fitur dipetakan ke qubit yang sesuai, , meninggalkan qubit dalam product state.
- Satu nilai numerik di-encode dalam satu waktu, bukan seluruh set fitur dari satu titik data.
- qubit diperlukan untuk fitur data, di mana . Sering kali kesetaraan berlaku di sini. Kita akan melihat bagaimana bisa terjadi di beberapa bagian berikutnya.
- Circuit kuantum yang dihasilkan memiliki kedalaman konstan (biasanya kedalaman 1 sebelum transpilasi).
Circuit kuantum kedalaman konstan membuatnya sangat cocok untuk hardware kuantum saat ini. Satu fitur tambahan dari encoding data menggunakan (dan khususnya, pilihan kita untuk menggunakan Y-axis angle encoding) adalah bahwa ia menciptakan state kuantum bernilai real yang bisa berguna untuk aplikasi tertentu. Untuk rotasi sumbu Y, data dipetakan dengan Gate rotasi sumbu Y dengan sudut bernilai real (Qiskit RYGate). Seperti dengan phase encoding (lihat di bawah), kami menyarankan agar kamu mengubah skala data sehingga , mencegah kehilangan informasi dan efek yang tidak diinginkan lainnya.
Kode Qiskit berikut merotasi satu qubit dari state awal untuk meng-encode nilai data .
from qiskit.quantum_info import Statevector
from math import pi
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
Kita akan mendefinisikan fungsi untuk memvisualisasikan aksi pada vektor state. Detail definisi fungsi tidak penting, tapi kemampuan untuk memvisualisasikan vektor state dan perubahannya itu penting.
import numpy as np
from qiskit.visualization.bloch import Bloch
from qiskit.visualization.state_visualization import _bloch_multivector_data
def plot_Nstates(states, axis, plot_trace_points=True):
"""This function plots N states to 1 Bloch sphere"""
bloch_vecs = [_bloch_multivector_data(s)[0] for s in states]
if axis is None:
bloch_plot = Bloch()
else:
bloch_plot = Bloch(axes=axis)
bloch_plot.add_vectors(bloch_vecs)
if len(states) > 1:
def rgba_map(x, num):
g = (0.95 - 0.05) / (num - 1)
i = 0.95 - g * num
y = g * x + i
return (0.0, y, 0.0, 0.7)
num = len(states)
bloch_plot.vector_color = [rgba_map(x, num) for x in range(1, num + 1)]
bloch_plot.vector_width = 3
bloch_plot.vector_style = "simple"
if plot_trace_points:
def trace_points(bloch_vec1, bloch_vec2):
# bloch_vec = (x,y,z)
n_points = 15
thetas = np.arccos([bloch_vec1[2], bloch_vec2[2]])
phis = np.arctan2(
[bloch_vec1[1], bloch_vec2[1]], [bloch_vec1[0], bloch_vec2[0]]
)
if phis[1] < 0:
phis[1] = phis[1] + 2 * pi
angles0 = np.linspace(phis[0], phis[1], n_points)
angles1 = np.linspace(thetas[0], thetas[1], n_points)
xp = np.cos(angles0) * np.sin(angles1)
yp = np.sin(angles0) * np.sin(angles1)
zp = np.cos(angles1)
pnts = [xp, yp, zp]
bloch_plot.add_points(pnts)
bloch_plot.point_color = "k"
bloch_plot.point_size = [4] * len(bloch_plot.points)
bloch_plot.point_marker = ["o"]
for i in range(len(bloch_vecs) - 1):
trace_points(bloch_vecs[i], bloch_vecs[i + 1])
bloch_plot.sphere_alpha = 0.05
bloch_plot.frame_alpha = 0.15
bloch_plot.figsize = [4, 4]
bloch_plot.render()
plot_Nstates(states, axis=None, plot_trace_points=True)

Itu baru satu fitur dari satu vektor data. Ketika meng-encode fitur ke dalam sudut rotasi dari qubit, misalnya untuk vektor data ke- product state yang di-encode akan terlihat seperti ini:
Kita perhatikan bahwa ini ekuivalen dengan
Cek pemahamanmu
Baca pertanyaan di bawah, pikirkan jawabanmu, lalu klik segitiga untuk melihat solusinya.
Encode vektor data menggunakan angle encoding, seperti yang dijelaskan di atas.
Jawaban:
qc = QuantumCircuit(3)
qc.ry(0, 0)
qc.ry(2 * math.pi / 4, 1)
qc.ry(2 * math.pi / 2, 2)
qc.draw(output="mpl")

Menggunakan angle encoding seperti yang dijelaskan di atas, berapa banyak qubit yang diperlukan untuk meng-encode 5 fitur?
Jawaban: 5
Phase encoding
Phase encoding sangat mirip dengan angle encoding yang dijelaskan di atas. Sudut fase dari sebuah qubit adalah sudut bernilai real terhadap sumbu dari sumbu +. Data dipetakan dengan rotasi fase, , di mana (lihat Qiskit PhaseGate untuk informasi lebih lanjut). Disarankan untuk mengubah skala data sehingga . Ini mencegah kehilangan informasi dan efek yang berpotensi tidak diinginkan lainnya[1,2].
Sebuah qubit sering diinisialisasi dalam state , yang merupakan eigenstate dari operator rotasi fase, artinya state qubit pertama-tama perlu dirotasi agar phase encoding dapat diimplementasikan. Oleh karena itu masuk akal untuk menginisialisasi state dengan Gate Hadamard: . Phase encoding pada satu qubit berarti memberikan fase relatif yang proporsional dengan nilai data:
Prosedur phase encoding memetakan setiap nilai fitur ke fase dari qubit yang sesuai, . Secara keseluruhan, phase encoding memiliki kedalaman Circuit 2, termasuk lapisan Hadamard, yang membuatnya menjadi skema encoding yang efisien. State multi-Qubit yang di-encode dengan phase ( qubit untuk fitur) adalah product state:
Kode Qiskit berikut pertama menyiapkan state awal satu qubit dengan merotasinya menggunakan Gate Hadamard, kemudian merotasinya lagi menggunakan Gate fase untuk meng-encode fitur data .
qc = QuantumCircuit(1)
qc.h(0) # Hadamard gate rotates state down to Bloch equator
state1 = Statevector.from_instruction(qc)
qc.p(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
qc.draw("mpl", scale=1)

Kita bisa memvisualisasikan rotasi dalam menggunakan fungsi plot_Nstates yang sudah kita definisikan.
plot_Nstates(states, axis=None, plot_trace_points=True)

Plot Bloch sphere menampilkan rotasi sumbu Z di mana . Panah hijau muda menunjukkan state akhir.
Phase encoding digunakan dalam banyak quantum feature map, khususnya feature map dan , serta Pauli feature map umum, di antara yang lain.
Cek pemahamanmu
Baca pertanyaan di bawah, pikirkan jawabanmu, lalu klik segitiga untuk melihat solusinya.
Berapa banyak qubit yang diperlukan untuk menggunakan phase encoding seperti yang dijelaskan di atas untuk menyimpan 8 fitur?
Jawaban: 8
Tulis kode untuk vektor menggunakan phase encoding.
Jawaban:
Mungkin ada banyak jawaban. Berikut satu contoh:
phase_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0]
qc = QuantumCircuit(len(phase_data))
for i in range(0, len(phase_data)):
qc.h(i)
qc.rz(phase_data[i] * 2 * math.pi / float(max(phase_data)), i)
qc.draw(output="mpl")

Dense angle encoding
Dense angle encoding (DAE) adalah kombinasi dari angle encoding dan phase encoding. DAE memungkinkan dua nilai fitur di-encode dalam satu qubit: satu sudut dengan sudut rotasi sumbu Y, dan yang lainnya dengan sudut rotasi sumbu : . DAE meng-encode dua fitur sebagai berikut:
Meng-encode dua fitur data ke satu qubit menghasilkan pengurangan dalam jumlah qubit yang diperlukan untuk encoding. Memperluas ini ke lebih banyak fitur, vektor data bisa di-encode sebagai:
DAE bisa digeneralisasi ke fungsi sembarang dari dua fitur alih-alih fungsi sinusoidal yang digunakan di sini. Ini disebut general qubit encoding[7].
Sebagai contoh DAE, kode di bawah meng-encode dan memvisualisasikan encoding fitur dan .
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(3 * pi / 8, 0)
state2 = Statevector.from_instruction(qc)
qc.rz(7 * pi / 4, 0)
state3 = Statevector.from_instruction(qc)
states = state1, state2, state3
plot_Nstates(states, axis=None, plot_trace_points=True)

Cek pemahamanmu
Baca pertanyaan di bawah, pikirkan jawabanmu, lalu klik segitiga untuk melihat solusinya.
Berdasarkan pembahasan di atas, berapa banyak qubit yang diperlukan untuk meng-encode 6 fitur menggunakan dense encoding?
Jawaban: 3
Tulis kode untuk memuat vektor menggunakan dense angle encoding.
Jawaban:
Perhatikan bahwa kita telah menambahkan padding dengan "0" pada daftar untuk menghindari masalah adanya satu parameter yang tidak terpakai dalam skema encoding kita.
dense_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5, 0]
qc = QuantumCircuit(int(len(dense_data) / 2))
entry = 0
for i in range(0, int(len(dense_data) / 2)):
qc.ry(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.rz(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.draw(output="mpl")

Encoding dengan feature map bawaan
Encoding di titik sembarang
Angle encoding, phase encoding, dan dense encoding menyiapkan product state dengan satu fitur yang di-encode di setiap qubit (atau dua fitur per qubit). Ini berbeda dari basis encoding dan amplitude encoding, di mana metode tersebut memanfaatkan entangled state. Tidak ada korespondensi 1:1 antara fitur data dan qubit. Dalam amplitude encoding, misalnya, kamu mungkin memiliki satu fitur sebagai amplitudo dari state dan fitur lain sebagai amplitudo untuk . Secara umum, metode yang melakukan encoding dalam product state menghasilkan Circuit yang lebih dangkal dan dapat menyimpan 1 atau 2 fitur di setiap qubit. Metode yang menggunakan entanglement dan mengasosiasikan fitur dengan state alih-alih qubit menghasilkan Circuit yang lebih dalam, dan rata-rata dapat menyimpan lebih banyak fitur per qubit.
Namun encoding tidak harus seluruhnya dalam product state atau seluruhnya dalam entangled state seperti pada amplitude encoding. Memang, banyak skema encoding yang sudah ada di Qiskit memungkinkan encoding baik sebelum maupun setelah layer entanglement, bukan hanya di awal. Ini dikenal sebagai "data reuploading". Untuk referensi terkait, lihat referensi [5] dan [6].
Di bagian ini, kita akan menggunakan dan memvisualisasikan beberapa skema encoding bawaan. Semua metode di bagian ini melakukan encoding fitur sebagai rotasi pada parameterized gate pada qubit, di mana . Perlu diingat bahwa memaksimalkan pemuatan data untuk jumlah qubit tertentu bukan satu-satunya pertimbangan. Dalam banyak kasus, kedalaman Circuit bisa menjadi pertimbangan yang bahkan lebih penting daripada jumlah qubit.
Efficient SU2
Contoh umum dan berguna dari encoding dengan entanglement adalah Circuit efficient_su2 dari Qiskit. Yang mengesankan, Circuit ini bisa, misalnya, melakukan encoding 8 fitur hanya pada 2 qubit. Mari kita lihat ini, lalu coba pahami bagaimana hal itu memungkinkan.
from qiskit.circuit.library import efficient_su2
circuit = efficient_su2(num_qubits=2, reps=1, insert_barriers=True)
circuit.decompose().draw(output="mpl")

Saat kita menuliskan state, kita akan menggunakan konvensi Qiskit bahwa qubit dengan signifikansi terendah diurutkan di posisi paling kanan, seperti pada atau State-state ini bisa menjadi sangat rumit dengan sangat cepat, dan contoh yang jarang ini mungkin membantu menjelaskan mengapa state semacam itu jarang dituliskan secara eksplisit.
Sistem kita dimulai dalam state Sampai barrier pertama (titik yang kita beri label ), state kita adalah:
Itu hanya dense encoding, yang sudah kita lihat sebelumnya. Sekarang setelah Gate CNOT, pada barrier kedua (), state kita adalah
Sekarang kita terapkan set rotasi qubit tunggal terakhir dan kumpulkan state-state yang sejenis untuk mendapatkan:
Ini mungkin terlalu rumit untuk dipahami. Sebagai gantinya, cukup mundur sebentar dan pikirkan berapa banyak parameter yang kita muat ke dalam state: delapan. Tapi kita hanya punya empat basis komputasi. Pada pandangan pertama, mungkin tampak bahwa kita telah memuat lebih banyak parameter dari yang masuk akal, karena state akhir dapat dituliskan sebagai . Perhatikan, bagaimanapun, bahwa setiap prefaktor bersifat kompleks! Ditulis seperti ini:
Kita bisa melihat bahwa kita memang memiliki delapan parameter pada state untuk melakukan encoding delapan fitur.
Dengan menambah jumlah qubit dan menambah jumlah pengulangan layer entanglement dan rotasi, kita bisa melakukan encoding jauh lebih banyak data. Menuliskan fungsi gelombang dengan cepat menjadi tidak traktabel. Tapi kita masih bisa melihat encoding dalam aksi.
Di sini kita melakukan encoding vektor data dengan 12 fitur, pada Circuit efficient_su2 3-qubit, menggunakan setiap parameterized gate untuk melakukan encoding fitur yang berbeda.
Dalam vektor data ini, fitur-fitur ditampilkan dalam urutan tertentu. Secara terpisah, tidak masalah apakah mereka di-encode dalam urutan ini atau sebaliknya. Yang penting adalah melacaknya dan bersikap konsisten. Perhatikan dalam diagram Circuit bahwa efficient_su2 mengasumsikan urutan encoding tertentu, khususnya mengisi layer pertama dari parameterized gate dari qubit 0 ke qubit 2, kemudian pindah ke layer berikutnya. Ini tidak konsisten maupun tidak konsisten dengan notasi little-endian, karena di sini fitur data tidak dapat diurutkan berdasarkan qubit a priori, sebelum Circuit encoding ditentukan.
x = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.1, 1.2]
circuit = efficient_su2(num_qubits=3, reps=1, insert_barriers=True)
encode = circuit.assign_parameters(x)
encode.decompose().draw(output="mpl")

Alih-alih menambah jumlah qubit, kamu mungkin memilih untuk menambah jumlah pengulangan layer entanglement dan rotasi. Tapi ada batasan seberapa banyak pengulangan yang berguna. Seperti yang telah disebutkan sebelumnya, ada trade-off: Circuit dengan lebih banyak qubit atau lebih banyak pengulangan layer entanglement dan rotasi mungkin menyimpan lebih banyak parameter, tapi melakukannya dengan kedalaman Circuit yang lebih besar. Kita akan kembali ke kedalaman beberapa feature map bawaan di bawah ini. Beberapa metode encoding berikutnya yang sudah ada di Qiskit memiliki "feature map" sebagai bagian dari namanya. Mari kita tegaskan kembali bahwa melakukan encoding data ke dalam quantum Circuit adalah sebuah feature mapping, dalam arti bahwa ia membawa data ke ruang baru: ruang Hilbert dari qubit yang terlibat. Hubungan antara dimensionalitas ruang fitur asli dan ruang Hilbert akan bergantung pada Circuit yang kamu gunakan untuk encoding.
Feature map
Feature map (ZFM) dapat diinterpretasikan sebagai perluasan alami dari phase encoding. ZFM terdiri dari layer-layer Gate qubit tunggal yang bergantian: layer Gate Hadamard dan layer Gate fase. Misalkan vektor data memiliki fitur. Quantum Circuit yang melakukan feature mapping direpresentasikan sebagai operator uniter yang bekerja pada state awal:
di mana adalah ground state -qubit. Notasi ini digunakan untuk konsistensi dengan referensi [4] Havlicek et al. Fitur data dipetakan satu-satu dengan qubit yang sesuai. Misalnya, jika kamu memiliki 8 fitur dalam vektor data, maka kamu akan menggunakan 8 qubit. Circuit ZFM terdiri dari pengulangan subCircuit yang terdiri dari layer Gate Hadamard dan layer Gate fase. Sebuah layer Hadamard terdiri dari Gate Hadamard yang bekerja pada setiap qubit dalam register -qubit, , dalam tahap algoritma yang sama. Deskripsi ini juga berlaku untuk layer Gate fase di mana qubit ke- dikenai . Setiap Gate memiliki satu fitur sebagai argumen, tapi layer Gate fase ( adalah fungsi dari vektor data. Circuit ZFM penuh dengan satu pengulangan unitarnya adalah:
Kemudian pengulangan dari uniter ini adalah
Fitur data, , dipetakan ke Gate fase dengan cara yang sama di semua pengulangan. State feature map ZFM adalah product state dan efisien untuk simulasi klasik[4].
Untuk mulai dengan contoh kecil, Circuit ZFM dua qubit dibuat menggunakan Qiskit dan digambar untuk menampilkan struktur Circuit yang sederhana. Dalam contoh ini, satu pengulangan, , diimplementasikan dengan vektor data . Perhatikan bahwa ini ditulis dalam urutan standar vektor dalam Python, yang berarti elemen ke- adalah Kita bebas melakukan encoding fitur ke- ini ke qubit ke- kita, atau ke qubit ke- kita. Sekali lagi, tidak selalu ada pemetaan 1:1 tunggal dari urutan fitur ke urutan qubit, karena feature map yang berbeda melakukan encoding jumlah fitur yang berbeda ke setiap qubit. Sekali lagi yang penting adalah kita sadar di mana setiap fitur di-encode. Saat memberikan daftar parameter ke feature map , ia akan melakukan encoding fitur 0 dari daftar ke qubit dengan signifikansi terendah yang memiliki parameterized gate, yaitu qubit 0. Jadi kita akan mengikuti konvensi tersebut saat melakukannya secara manual. Kita akan melakukan encoding pada qubit ke-, dan pada qubit ke-.
Operator uniter Circuit ZFM bekerja pada state awal dengan cara berikut:
Formula telah disusun ulang di sekitar hasil kali tensor untuk menekankan operasi pada setiap qubit. Kode Qiskit berikut menggunakan Gate Hadamard dan fase secara eksplisit untuk menunjukkan struktur ZFM:
qc0 = QuantumCircuit(1)
qc1 = QuantumCircuit(1)
qc0.h(0)
qc0.p(pi / 2, 0)
qc1.h(0)
qc1.p(pi / 3, 0)
# Combine circuits qc0 and qc1 into 1 circuit
qc = QuantumCircuit(2)
qc.compose(qc0, [0], inplace=True)
qc.compose(qc1, [1], inplace=True)
qc.draw("mpl", scale=1)

Sekarang kita melakukan encoding vektor data yang sama ke Circuit ZFM dengan tiga pengulangan, , menggunakan kelas z_feature_map dari Qiskit, yang secara keseluruhan memberikan kita feature map kuantum . Secara default dalam kelas z_feature_map, parameter dikalikan dengan 2 sebelum dipetakan ke Gate fase . Untuk mereproduksi encoding yang sama seperti di atas, kita bagi dengan 2.
from qiskit.circuit.library import z_feature_map
zfeature_map = z_feature_map(feature_dimension=2, reps=3)
zfeature_map = zfeature_map.assign_parameters([(1 / 2) * pi / 2, (1 / 2) * pi / 3])
zfeature_map.decompose().draw("mpl")

Jelas ini adalah pemetaan yang berbeda dari yang dilakukan secara manual di atas, tapi perhatikan konsistensi dalam urutan parameter: sekali lagi di-encode pada qubit ke-.
Kamu bisa menggunakan ZFM melalui kelas ZFM dari Qiskit; kamu juga bisa menggunakan struktur ini sebagai inspirasi untuk membangun feature mapping sendiri.
Feature map
Feature map (ZZFM) memperluas ZFM dengan menyertakan Gate entanglement dua qubit, khususnya Gate rotasi . ZZFM diduga umumnya mahal untuk dihitung pada komputer klasik, tidak seperti ZFM.
mengimplementasikan interaksi dan bersifat entanglement maksimal untuk . dapat didekomposisi menjadi serangkaian Gate pada dua qubit, seperti yang ditunjukkan dalam kode Qiskit berikut menggunakan Gate RZZ dan metode kelas QuantumCircuit decompose. Kita melakukan encoding satu fitur dari vektor data :
qc = QuantumCircuit(2)
qc.rzz(pi, 0, 1)
qc.draw("mpl", scale=1)

Seperti yang sering terjadi, kita melihat ini direpresentasikan sebagai unit tunggal seperti Gate, sampai kita menggunakan .decompose() untuk melihat semua Gate penyusunnya.
qc.decompose().draw("mpl", scale=1)

Data dipetakan dengan rotasi fase pada qubit kedua. Gate melakukan entanglement dua qubit yang dioperasikannya dengan tingkat entanglement yang ditentukan oleh nilai fitur yang di-encode.
Circuit ZZFM penuh terdiri dari Gate Hadamard dan Gate fase, seperti dalam ZFM, diikuti oleh entanglement yang dijelaskan di atas. Satu pengulangan dari Circuit ZZFM adalah:
di mana berisi layer Gate ZZ yang terstruktur oleh skema entanglement. Beberapa skema entanglement ditunjukkan dalam blok kode di bawah ini. Struktur juga mencakup fungsi yang menggabungkan fitur data dari qubit yang di-entangle dengan cara berikut. Katakanlah Gate akan diterapkan pada qubit dan . Dalam layer fase, qubit-qubit ini memiliki Gate fase yang melakukan encoding dan pada mereka, masing-masing. Argumen dari tidak akan hanya salah satu dari fitur ini atau yang lainnya, tapi sebuah fungsi yang sering dilambangkan dengan (jangan keliru dengan sudut azimut):
Kita akan melihat ini dalam beberapa contoh di bawah ini. Perluasan ke beberapa pengulangan sama seperti pada kasus z_feature_map:
Karena operator telah meningkat dalam kerumitan, mari kita pertama-tama melakukan encoding vektor data dengan ZZFM dua qubit dan satu pengulangan menggunakan kode berikut:
from qiskit.circuit.library import zz_feature_map
feature_dim = 2
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose(reps=1).draw("mpl", scale=1)

Secara default dalam Qiskit, fitur dipetakan bersama ke oleh fungsi pemetaan ini . Qiskit memungkinkan pengguna untuk mengkustomisasi fungsi (atau di mana adalah himpunan pasangan qubit yang terhubung melalui Gate ) sebagai langkah pra-pemrosesan.
Beralih ke vektor data empat dimensi dan memetakannya ke ZZFM empat qubit dengan satu pengulangan, kita mulai bisa melihat pemetaan untuk berbagai pasangan qubit. Kita juga bisa melihat arti dari entanglement "linear":
feature_dim = 4
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose().draw("mpl", scale=1)

Dalam skema entanglement linear, pasangan qubit yang berdekatan (bernomor) dalam Circuit ini saling ter-entangle. Ada skema entanglement bawaan lainnya dalam Qiskit, termasuk circular dan full.
Feature map Pauli
Feature map Pauli (PFM) adalah generalisasi dari ZFM dan ZZFM untuk menggunakan Gate Pauli sembarang. Feature map Pauli memiliki bentuk yang sangat mirip dengan dua feature map sebelumnya. Untuk pengulangan encoding fitur dari vektor
Untuk PFM, digeneralisasikan ke operator uniter ekspansi Pauli. Di sini kita menyajikan bentuk yang lebih umum dari feature map yang telah dipertimbangkan sejauh ini:
di mana adalah operator Pauli, . Di sini adalah himpunan semua konektivitas qubit yang ditentukan oleh feature map, termasuk himpunan qubit yang dikenai Gate qubit tunggal. Yaitu, untuk feature map di mana qubit 0 dikenai Gate fase, dan qubit 2 dan 3 dikenai Gate , himpunan akan mencakup . berjalan melalui semua elemen dari himpunan tersebut. Dalam feature map sebelumnya, fungsi terlibat baik secara eksklusif dengan Gate qubit tunggal atau secara eksklusif dengan Gate dua qubit. Di sini, kita mendefinisikannya secara umum:
Untuk dokumentasi, lihat dokumentasi kelas Qiskit Pauli feature map). Dalam ZZFM, operator dibatasi pada .
Salah satu cara untuk memahami uniter di atas adalah melalui analogi dengan propagator dalam sistem fisika. Uniter di atas adalah operator evolusi uniter, , untuk Hamiltonian, , yang mirip dengan model Ising, di mana parameter waktu, , digantikan dengan nilai data untuk mendorong evolusi. Ekspansi operator uniter ini memberikan Circuit PFM. Konektivitas entanglement dalam dapat diinterpretasikan sebagai kopling Ising dalam kisi spin.
Mari kita pertimbangkan contoh operator Pauli dan yang mewakili interaksi bertipe Ising tersebut. Qiskit menyediakan kelas pauli_feature_map untuk menginstansiasi PFM dengan pilihan Gate qubit tunggal dan -qubit, yang dalam contoh ini akan diteruskan sebagai string Pauli 'Y' dan 'XX'. Biasanya, adalah 1 atau 2 untuk interaksi qubit tunggal dan dua qubit, masing-masing. Skema entanglement adalah "linear", yang berarti hanya qubit yang bertetangga dalam Circuit kuantum yang terhubung. Perhatikan bahwa ini tidak berkorespondensi dengan qubit yang bertetangga pada komputer kuantum itu sendiri, karena Circuit kuantum ini adalah lapisan abstraksi.
from qiskit.circuit.library import pauli_feature_map
feature_dim = 3
pfmap = pauli_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1, paulis=["Y", "XX"]
)
pfmap.decompose().draw("mpl", scale=1.5)

Qiskit menyediakan parameter, , dalam feature map Pauli untuk mengontrol penskalaan rotasi Pauli.
Nilai default dari adalah . Dengan mengoptimalkan nilainya dalam interval, misalnya, kita bisa lebih menyelaraskan kernel kuantum dengan data.
Galeri feature map Pauli
Di sini kita memvisualisasikan berbagai feature map Pauli untuk Circuit dua qubit untuk mendapatkan gambaran yang lebih baik tentang berbagai kemungkinan.
from qiskit.visualization import circuit_drawer
import matplotlib.pyplot as plt
feature_dim = 2
fig, axs = plt.subplots(9, 2)
i_plot = 0
for paulis in [
["I"],
["X"],
["Y"],
["Z"],
["XX"],
["XY"],
["XZ"],
["YY"],
["YZ"],
["ZZ"],
["X", "ZZ"],
["Y", "ZZ"],
["Z", "ZZ"],
["X", "YZ"],
["Y", "YZ"],
["Z", "YZ"],
["YY", "ZZ"],
["XY", "ZZ"],
]:
pfmap = pauli_feature_map(feature_dimension=feature_dim, paulis=paulis, reps=1)
circuit_drawer(
pfmap.decompose(),
output="mpl",
style={"backgroundcolor": "#EEEEEE"},
ax=axs[int((i_plot - i_plot % 2) / 2), i_plot % 2],
)
axs[int((i_plot - i_plot % 2) / 2), i_plot % 2].title.set_text(paulis)
i_plot += 1
fig.set_figheight(16)
fig.set_figwidth(16)
Yang di atas tentu saja dapat diperluas untuk mencakup permutasi dan pengulangan lain dari matriks Pauli. Pelajar didorong untuk bereksperimen dengan opsi-opsi tersebut.
Tinjauan feature map bawaan
Kamu telah melihat beberapa skema untuk melakukan encoding data ke dalam quantum Circuit:
- Basis encoding
- Amplitude encoding
- Angle encoding
- Phase encoding
- Dense encoding
Kamu telah melihat cara membangun feature map sendiri menggunakan skema encoding ini, dan kamu telah melihat empat feature map bawaan yang memanfaatkan angle dan phase encoding:
- Efficient SU2
- Feature map Z
- Feature map ZZ
- Feature map Pauli
Feature map bawaan ini berbeda satu sama lain dalam beberapa hal:
- Kedalaman untuk jumlah fitur yang di-encode tertentu
- Jumlah qubit yang dibutuhkan untuk jumlah fitur tertentu
- Tingkat entanglement (jelas terkait dengan perbedaan lainnya)
Kode di bawah ini menerapkan empat feature map bawaan ini pada encoding sebuah set fitur, dan memplot kedalaman dua qubit dari Circuit yang dihasilkan. Karena tingkat error dua qubit jauh lebih tinggi dari tingkat error Gate qubit tunggal, mungkin paling menarik untuk melihat kedalaman Gate dua qubit. Dalam kode di bawah ini, kita mendapatkan jumlah semua Gate dalam sebuah sirkuit dengan pertama-tama mendekomposisi Circuit tersebut kemudian menggunakan count_ops(), seperti yang ditunjukkan di bawah ini. Di sini Gate dua qubit yang kita minati adalah Gate 'cx':
# Initializing parameters and empty lists for depths
x = [0.1, 0.2]
n_data = []
zz2gates = []
su22gates = []
z2gates = []
p2gates = []
# Generating feature maps
for n in range(3, 10):
x.append(n / 10)
zzcircuit = zz_feature_map(n, reps=1, insert_barriers=True)
zcircuit = z_feature_map(n, reps=1, insert_barriers=True)
su2circuit = efficient_su2(n, reps=1, insert_barriers=True)
pcircuit = pauli_feature_map(n, reps=1, paulis=["XX"], insert_barriers=True)
# Getting the cx depths
zzcx = zzcircuit.decompose().count_ops().get("cx")
zcx = zcircuit.decompose().count_ops().get("cx")
su2cx = su2circuit.decompose().count_ops().get("cx")
pcx = pcircuit.decompose().count_ops().get("cx")
# Appending the cx gate counts to the lists. We shift the zz and Pauli data points,
# because they overlap.
n_data.append(n)
zz2gates.append(zzcx - 0.5)
z2gates.append(0)
su22gates.append(su2cx)
p2gates.append(pcx + 0.5)
# Plot the output
plt.plot(n_data, p2gates, "bo")
plt.plot(n_data, zz2gates, "ro")
plt.plot(n_data, su22gates, "yo")
plt.plot(n_data, z2gates, "go")
plt.ylabel("CX Gates")
plt.xlabel("Data elements")
plt.legend(["Pauli", "ZZ", "SU2", "Z"])
# plt.suptitle('zz_feature_map(n)')
plt.show()
Secara umum feature map Pauli dan ZZ akan menghasilkan kedalaman Circuit yang lebih besar dan jumlah Gate 2-qubit yang lebih tinggi dibandingkan efficient_su2 dan feature map Z.
Karena feature map yang sudah ada di Qiskit berlaku secara luas, kita sering tidak perlu merancang sendiri, terutama dalam fase pembelajaran. Namun, para ahli dalam quantum machine learning kemungkinan akan kembali ke subjek merancang feature mapping mereka sendiri, saat mereka menghadapi dua tantangan yang rumit:
-
Hardware modern: keberadaan noise dan overhead besar dari kode koreksi error berarti aplikasi masa kini perlu mempertimbangkan hal-hal seperti efisiensi hardware dan minimisasi kedalaman Gate dua qubit.
-
Pemetaan yang sesuai dengan masalah yang ada: Satu hal untuk mengatakan bahwa
zz_feature_map, misalnya, sulit untuk disimulasikan secara klasik, dan karena itu menarik. Hal yang sama sekali berbeda adalahzz_feature_mapyang idealnya cocok untuk tugas machine learning atau dataset kamu. Performa dari berbagai parameterized quantum circuit pada berbagai jenis data adalah bidang investigasi yang aktif.
Kita menutup dengan catatan tentang efisiensi hardware.
Feature mapping yang efisien dari sisi hardware
Feature mapping yang efisien dari sisi hardware adalah yang mempertimbangkan kendala komputer kuantum nyata, demi mengurangi noise dan error dalam komputasi. Saat menjalankan quantum Circuit pada komputer kuantum near-term, ada banyak strategi untuk memitigasi noise yang melekat pada hardware. Satu strategi utama untuk efisiensi hardware adalah minimisasi kedalaman quantum Circuit sehingga noise dan dekoherensi memiliki lebih sedikit waktu untuk merusak komputasi. Kedalaman quantum Circuit adalah jumlah langkah Gate yang sejajar waktu yang diperlukan untuk menyelesaikan seluruh komputasi (setelah optimasi Circuit)[5]. Ingat bahwa kedalaman Circuit logis abstrak mungkin jauh lebih rendah dari kedalaman setelah Circuit di-transpile untuk komputer kuantum nyata.
Transpilation adalah proses mengkonversi quantum Circuit dari abstraksi tingkat tinggi ke satu yang siap untuk dijalankan pada komputer kuantum nyata, dengan mempertimbangkan kendala hardware. Komputer kuantum memiliki set Gate qubit tunggal dan dua qubit yang native. Ini berarti semua Gate dalam kode Qiskit harus di-transpile ke dalam set Gate hardware native. Misalnya, dalam ibm_torino, QPU yang menampilkan prosesor Heron r1 dan selesai pada 2023, Gate native atau basis adalah {CZ, ID, RZ, SX, X}. Ini adalah Gate controlled-Z dua qubit, dan Gate qubit tunggal yang disebut identity, rotasi-, akar kuadrat dari NOT, dan NOT, masing-masing, menyediakan set universal. Saat mengimplementasikan Gate multi-qubit sebagai subCircuit yang setara, Gate dua qubit fisik diperlukan, beserta Gate qubit tunggal lain yang tersedia di hardware. Selain itu, untuk melakukan Gate dua qubit pada pasangan qubit yang tidak terhubung secara fisik, Gate SWAP ditambahkan untuk memindahkan state qubit antara qubit agar memungkinkan kopling, yang mengarah pada perpanjangan Circuit yang tidak terhindarkan. Menggunakan argumen optimization yang dapat diatur dari 0 hingga level tertinggi yaitu 3. Untuk kontrol dan kustomisasi yang lebih besar, pipeline Transpiler dapat dikelola dengan Qiskit Pass Manager. Lihat dokumentasi Qiskit Transpiler untuk informasi lebih lanjut tentang transpilation.
Dalam Havlicek et al. 2019 [2], salah satu cara penulis mencapai efisiensi hardware adalah dengan menggunakan feature map karena merupakan ekspansi orde kedua (lihat bagian "Feature map " di atas). Ekspansi orde- memiliki Gate -qubit. Komputer kuantum IBM® tidak memiliki Gate -qubit native, di mana , sehingga untuk mengimplementasikannya diperlukan dekomposisi ke Gate CNOT dua qubit yang tersedia di hardware. Cara kedua penulis meminimalkan kedalaman adalah dengan memilih topologi kopling yang dipetakan langsung ke kopling arsitektur. Optimasi lebih lanjut yang mereka lakukan adalah menargetkan subCircuit hardware yang berkinerja tinggi dan terhubung dengan baik. Hal tambahan yang perlu dipertimbangkan adalah meminimalkan jumlah pengulangan feature map dan memilih skema entanglement kedalaman rendah atau "linear" yang dikustomisasi alih-alih skema "full" yang melakukan entanglement semua qubit.

Grafik di atas menunjukkan jaringan node dan edge yang mewakili qubit fisik dan kopling hardware, masing-masing. Peta kopling dan performa dari ibm_torino ditunjukkan dengan semua kemungkinan Gate kopling CZ dua qubit. Qubit diberi kode warna pada skala berdasarkan waktu relaksasi T1 dalam mikrodetik (μs), di mana waktu T1 yang lebih lama lebih baik dan dalam warna yang lebih terang. Edge kopling diberi kode warna berdasarkan error CZ, di mana warna yang lebih gelap lebih baik. Informasi tentang spesifikasi hardware dapat diakses dalam skema konfigurasi Backend hardware IBMQBackend.configuration().
Referensi
- Maria Schuld and Francesco Petruccione, Supervised Learning with Quantum Computers, Springer 2018, doi:10.1007/978-3-319-96424-9.
- Vojtech Havlicek et al., "Supervised Learning with Quantum Enhanced Feature Spaces." Nature, vol. 567 (2019): 209–212. https://arxiv.org/abs/1804.11326.
- Ryan LaRose and Brian Coyle, "Robust data encodings for quantum classifiers", Physical Review A 102, 032420 (2020), doi:10.1103/PhysRevA.102.032420, arXiv:2003.01695.
- Lou Grover and Terry Rudolph. "Creating Superpositions That Correspond to Efficiently Integrable Probability Distributions." arXiv:quant-ph/0208112, August 15, 2002, https://arxiv.org/abs/quant-ph/0208112.
- Adrián Pérez-Salinas, Alba Cervera-Lierta, Elies Gil-Fuster, José I. Latorre, "Data re-uploading for a universal quantum classifier", Quantum 4, 226 (2020), ArXiv.org/abs/1907.02085.
- Maria Schuld, Ryan Sweke, Johannes Jakob Meyer, "The effect of data encoding on the expressive power of variational quantum machine learning models", Phys. Rev. A 103, 032430 (2021), arxiv.org/abs/2008.08605
import qiskit
qiskit.version.get_version_info()